Convolutional Neural Networks for Sentence Classification
本文将CNN和NLP结合;
介绍了一系列的对比实验,实验结果说明了:
- 一个简单的(单层神经网络)的CNN模型
- 一点超参数的调节(Filter的个数)
- static word vector
- 另外,对cnn模型进行了小改动:将static vectors和non static vectors变成cnn模型中的两个channels,尤如图像中的rgb三通道。
non-static就是词向量随着模型训练变化,这样的好处是词向量可以根据数据集做适当调整
static就是直接使用word2vec训练好的词向量即可
卷积之后得到的列向量维度也是不同的,可以通过pooling来消除句子之间长度不同的差异
Pre-trained Word Vectors
当手头上没有large supervised training dataset的时候,用word2vec(或相似的unsupervised nlp模型得到)初始化word vectors能提高performance。
Model
这是本文的模型,基本也就是CNN的结构
左边是一个n*k的矩阵,表示一句话的n个词语,每个词语是一个k维向量
(这里word2vec)
然后设置一个滑窗的长度h,用这个滑窗滑过整个矩阵,然后通过下面这个公式的计算,算出h对应的一个特征的向量c
w是权重,b是偏移量
f就是一个非线性函数
(卷积核)
形成这个向量,称为feature map
我们可以通过改变h的大小,生成很多feature maps
然后对于每个feature map,采取选出这个向量中的最大值,(意在找到最重要的特征)
同时也解决了每个feature map不等长,统一了维度的问题
然后再将这个传递到 全连接层
这是一个softmax层(因为涉及到句子的分类问题)
输出的就是对于不同的label的概率分布
数据集相对较小,很容易就会发生过拟合现象
所以这里引如dropout来减少过拟合现象。
就是产生一定的概率来mask掉一些点
Model Variations
- CNN-rand : 所有的word vector都是随机初始化的,在训练过程中更新
- CNN-static : word vector用word2vec得出的结果,在整个train process中所有的words保持不变,只学习其他参数
- CNN-non-static : pretrained vector在训练过程中要被fine-tuned
- CNN-multichannel : two sets of word vectors. 初始化时两个channel都直接赋值word2vec得出的结果,每个filter也会分别applied到两个channel,但是训练过程中只有一个channel会进行BP
模型中除了这些参数改变,其他参数相同。
模型根据词向量的不同分为四种:
- CNN-rand,所有的词向量都随机初始化,并且作为模型参数进行训练。
- CNN-static,即用word2vec预训练好的向量(Google News),在训练过程中不更新词向量,句中若有单词不在预训练好的词典中,则用随机数来代替。
- CNN-non-static,根据不同的分类任务,进行相应的词向量预训练。
- CNN-multichannel,两套词向量构造出的句子矩阵作为两个通道,在误差反向传播时,只更新一组词向量,保持另外一组不变。
在七组数据集上进行了对比实验,证明了单层的CNN在文本分类任务中的有效性,同时也说明了用无监督学习来的词向量对于很多nlp任务都非常有意义。
static模型中word2vec预训练出的词向量会把good和bad当做相似的词,在sentiment classification任务中将会导致错误的结果,而non-static模型因为用了当前task dataset作为训练数据,不会存在这样的问题。具体可参看下图:
关于two channels of word vectors
one channel将word2vec得到的结果直接static的传入整个模型,另一个channel在BP训练过程中要进行fine-tune。每一个filter都要分别应用到这两个channels上。
例如上图中就能看出,系统有2 filters,对2个channels分别卷积后得到4 stacks。
Regularization
这里用到了dropout和l2正则项,避免过拟合
dropout就是将pooling之后的结果随机mask一部分值
比如,我们在这里pooling之后的结果是z,我们将z处理成y之后向前传递的时候,
然后我们就做一个 and 操作
每一次梯度下降,调整参数的时候,依靠这个阈值s来约束中间的参数
Static vs. Non-static Representations
一句话,non-static更适应specific task
Conclusion
CNN在NLP的一个尝试,并且效果还不错
说明了,pre-trained的word vector 是deep learning在NLP领域重要的组成部分
神经网络各层
- 对于文本任务,输入层自然使用了word embedding来做input data representation。
- 接下来是卷积层,大家在图像处理中经常看到的卷积核都是正方形的,比如44,然后在整张image上沿宽和高逐步移动进行卷积操作。但是nlp中输入的“image”是一个词矩阵,比如n个words,每个word用200维的vector表示的话,这个”image”就是n200的矩阵,卷积核只在高度上已经滑动,在宽度上和word vector的维度一致(=200),也就是说每次窗口滑动过的位置都是完整的单词,不会将几个单词的一部分“vector”进行卷积,这也保证了word作为语言中最小粒度的合理性。(当然,如果研究的粒度是character-level而不是word-level,需要另外的方式处理)
- 由于卷积核和word embedding的宽度一致,一个卷积核对于一个sentence,卷积后得到的结果是一个vector, shape=(sentence_len - filter_window + 1, 1),那么,在max-pooling后得到的就是一个Scalar。所以,这点也是和图像卷积的不同之处,需要注意一下。
- 正是由于max-pooling后只是得到一个scalar,在nlp中,会实施多个filter_window_size(比如3,4,5个words的宽度分别作为卷积的窗口大小),每个window_size又有num_filters个(比如64个)卷积核。一个卷积核得到的只是一个scalar太孤单了,智慧的人们就将相同window_size卷积出来的num_filter个scalar组合在一起,组成这个window_size下的feature_vector。
- 最后再将所有window_size下的feature_vector也组合成一个single vector,作为最后一层softmax的输入。
重要的事情说三遍:一个卷积核对于一个句子,convolution后得到的是一个vector;max-pooling后,得到的是一个scalar。
关于model
- filter windows: [3,4,5]
- filter maps: 100 for each filter window
- dropout rate: 0.5
- l2 constraint: 3
- randomly select 10% of training data as dev set(early stopping)
- word2vec(google news) as initial input, dim = 300
- sentence of length: n, padding where necessary
- number of target classes
- dataset size
- vocabulary size
cnn用在NLP
each row is vector that represents a word. Typically, these vectors are word embeddings (low-dimensional representations) like word2vec or GloVe, but they could also be one-hot vectors that index the word into a vocabulary. For a 10 word sentence using a 100-dimensional embedding we would have a 10×100 matrix as our input. That’s our “image”.
In vision, our filters slide over local patches of an image, but in NLP we typically use filters that slide over full rows of the matrix (words). Thus, the “width” of our filters is usually the same as the width of the input matrix. The height, or region size, may vary, but sliding windows over 2-5 words at a time is typical.
TextCNN详细过程:第一层是图中最左边的7乘5的句子矩阵,每行是词向量,维度=5,这个可以类比为图像中的原始像素点了。然后经过有 filter_size=(2,3,4) 的一维卷积层,每个filter_size 有两个输出 channel。第三层是一个1-max pooling层,这样不同长度句子经过pooling层之后都能变成定长的表示了,最后接一层全连接的 softmax 层,输出每个类别的概率。
特征:这里的特征就是词向量,有静态(static)和非静态(non-static)方式。static方式采用比如word2vec预训练的词向量,训练过程不更新词向量,实质上属于迁移学习了,特别是数据量比较小的情况下,采用静态的词向量往往效果不错。non-static则是在训练过程中更新词向量。推荐的方式是 non-static 中的 fine-tunning方式,它是以预训练(pre-train)的word2vec向量初始化词向量,训练过程中调整词向量,能加速收敛,当然如果有充足的训练数据和资源,直接随机初始化词向量效果也是可以的。
通道(Channels):图像中可以利用 (R, G, B) 作为不同channel,而文本的输入的channel通常是不同方式的embedding方式(比如 word2vec或Glove),实践中也有利用静态词向量和fine-tunning词向量作为不同channel的做法。
一维卷积(conv-1d):图像是二维数据,经过词向量表达的文本为一维数据,因此在TextCNN卷积用的是一维卷积。一维卷积带来的问题是需要设计通过不同 filter_size 的 filter 获取不同宽度的视野。
Pooling层:利用CNN解决文本分类问题的文章还是很多的,比如这篇 A Convolutional Neural Network for Modelling Sentences** 最有意思的输入是在 pooling 改成 (dynamic) k-max pooling ,pooling阶段保留 k 个最大的信息,保留了全局的序列信息。比如在情感分析场景,举个例子:
“ 我觉得这个地方景色还不错,但是人也实在太多了 ”
- 1
虽然前半部分体现情感是正向的,全局文本表达的是偏负面的情感,利用 k-max pooling能够很好捕捉这类信息。
Pooling Layers
Channels
For example, in image recognition you typically have RGB (red, green, blue) channels. You can apply convolutions across channels,
论文翻译(谷歌翻译的结果)
摘要
我们报告了一系列用卷积神经网络(CNN)进行的实验,这些实验训练了用于句子级别分类任务的预训练词语驱动器。 我们展示了一个简单的CNN,具有极大的参数调节和静态驱动器,可以在多个基准测试中取得优异的结果。 通过微调学习任务特定的向量可以进一步提高性能。 我们还提出了一个对架构的简单修改,以允许使用任务特定和静态向量。 本文讨论的CNN模型改善了7项任务中的4项工作,其中包括情绪分析和问题分类。
介绍
近年来,深度学习模型在计算机视觉(Krizhevsky等,2012)和语音识别(Graves et al。,2013)方面取得了显着的成果。 在自然语言处理中,大部分深入学习方法的工作涉及到通过神经语言模型学习单词向量表达(Bengio et al。,2003; Yih et al。,2011; Mikolov et al。,2013 ),并对所学习的词向量执行分类(Collobert等,2011)。 词汇向量,其中单词从稀疏的1-V编码(这里V是词汇大小)经由隐藏层投影到较低维度向量空间上,本质上是对其维度中的单词的语义特征进行编码的特征提取器。 在这种密集的表示中,语义上紧密的词在低维向量空间中同样是近似的欧几里德或余弦距离。
卷积神经网络(CNN)利用应用于局部特征的卷积滤波器的层(LeCun等,1998)。 最初为计算机视觉发明,CNN模型随后被证明对NLP有效,在语义解析(Yih et al。,2014),搜索查询检索(Shen et al。,2014),语言建模(Kalch - brenner et al。,2014)和其他传统的NLP任务(Collobert等,2011)。
在目前的工作中,我们在从无监督神经语言模型获得的单词向量之上训练一个简单的CNN卷积卷积。 这些载体由Mikolov等人 (2013年)在Google新闻1000亿字节,并且是公开的。我们最初保持向量静态,只学习模型的其他参数。 尽管对超参数进行了很少的调整,但是这种简单的模型在多个基准上取得了出色的结果,表明预先训练的矢量是可以用于各种分类任务的“通用”特征输出器。 通过微调学习任务特定的向量可以进一步改进。 我们最后描述了对架构的简单修改,以允许通过具有多个通道来使用预训练和任务特定向量。
我们的工作在哲学上与Razavian等人相似 (2014)显示,对于图像分类,从预先训练的深度学习模型获得的特征提取器在各种任务上表现良好 - 包括与原始任务不同的任务,特征提取器 受过训练
Model
如图1所示的模型架构是Collobert等人的CNN架构的一个轻微变体。(2011年)。 令xi∈Rk是对应于句子中第i个词的k维字向量。 长度为n(需要填充)的句子表示为x1:n =x1⊕x2⊕…⊕xn,
其中⊕是级联算子。 一般来说,令xi:i + j是指xi,xi + 1,…的连接。。。 ,xi + j。 卷积运算涉及一个滤波器∈Rhk,该滤波器应用于h字的窗口以产生新的特征。 例如,从单词xi:i + h-1的窗口生成特征ci
这里b∈R是偏置项,f是诸如双曲正切之类的非线性函数。 该过滤器应用于句子{x1:h,x2:h + 1,…中的每个可能的单词窗口。。。 ,xn-h + 1:n}以产生特征图
其中c∈Rn-h + 1。 然后,我们然后在特征图上应用最大超时池操作(Collobert等,2011),并将最大值c = max {c}作为与该特定过滤器对应的特征。 这个想法是为每个特征图捕获最重要的功能 - 具有最高价值的特征。 这种汇总方案自然地处理可变句长度。
我们描述了从一个过滤器中提取一个特征的过程。 该模型使用多个过滤器(具有不同的窗口大小)来获得多个功能。 这些特征形成倒数第二层,并传递给完全连接的softmax层,其输出是标签上的概率分布。
在其中一个模型变体中,我们尝试使用两个“向量通道”,一个在训练中保持静态,另一个通过反向传播进行微调(第3.2节).2在多通道架构中,如图1所示 ,将每个滤波器应用于两个通道,并将结果加到计算公式(2)中的ci。 该模型在其他方面相当于单通道架构。
Regularization
为了正规化,我们在倒数第二层上采用辍学,对权重向量的l2范数有约束(Hinton et al。,2012)。 辍学可以防止隐藏单元随机退出的共同适配,即在后置传播过程中隐藏单元的设置为零。 也就是说,给定倒数第二层z = [c1,...,cm](注意这里我们有m个滤波器),而不是使用
- 1
用于正向传播中的输出单元y,dropout使用
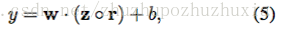
- 1
其中◦是元素乘法运算符,r∈Rm是概率p为1的伯努利随机变量的“掩蔽”向量。仅通过未屏蔽单位反向传播渐变。 在测试时间,所学习的权重向量按p进行缩放,使得w = pw,并且使用w(不丢失)来评估不可见的灵敏度。 我们另外通过在梯度下降步骤之后,当|| w || 2> s重新缩放w以使|| w || 2 = s约束权重向量的l2正则。
Datasets and Experimental Setup数据集和实验设置
MR:每次评论一个句子的电影评论。 分类涉及检测阳性/阴性评估(Pang和Lee,2005)
SST-1:斯坦福情报树组织 - MR的扩展,但提供火车/ dev /测试分裂和细粒度标签(非常有意义,积极,中立,消极,非常负面),由Socher et人。(2013)0.4
SST-2:与SST-1相同,但中性回复被删除,二进制标签。
- 1
•Subj:主观性数据集,其任务是将句子分类为主观或客观的(Pang和Lee,2004)。
•TREC:TREC问题数据集 - 任务将问题分为6个问题类型(问题是关于人,地点,数字信息等)(Li和Roth,2002).5
•CR:各种产品(相机,MP3等)的客户评价。 任务是预测潜在/负面评价(胡和刘,2004)
•MPQA:MPQA数据集的意见极性检测子任务(Wiebe et al。,2005).7
Hyperparameters and Training超参和训练
对于我们使用的所有数据集:整流线性单位,滤波器窗口(h)为3,4,5,每个具有100个特征图,辍学率(p)为0.5,l2约束(s)为3,小批量为50 这些值是通过SST-2开发集上的网格搜索来选择的。
除了早期停止开发集之外,我们不会执行任何数据集特定的调优。 对于没有标准开发集的数据集,我们随机选择10%的培训数据作为开发集dev。 训练是通过Addersta更新规则(Zeiler,2012)随机降级的混合小批量完成的。
Pre-trained Word Vectors
使用从无监督神经语言模型获得的词矢量初始化是一种流行的方法,在没有大型监督训练集的情况下提高性能(Collobert等,2011; Socher等,2011; Iyyer等,2014)。 我们使用公开提供的word2vec向量,这些向量来自Google新闻1000亿字。 载体的维数为300,并使用连续的词汇架构进行训练(Mikolov等,2013)。 在一组预训练词中不存在的词被随机地初始化。
Model Variations
我们尝试模型的几个变体。
•CNN-rand:我们的基准模型,其中所有单词随机初始化,然后在训练过程中进行修改。
•CNN-static:具有来自word2vec的预训练矢量的模型。 所有的单词 - 包括未知的 - 被初始化的单词 - 保持静态,只有模型的其他参数被学习。
•CNN非静态:与上述相同,但对每个任务进行微调。
•CNN多通道:具有两组字矢量的模型。 每组向量被视为“通道”,每个滤波器都应用于两个通道,但梯度只能通过其中一个通道进行反向传播。 因此,该模型能够微调一组向量,同时保持其他静态。 两个通道都用word2vec初始化。
为了解决上述变化与其他随机因素的影响,我们消除了其他随机因素 - CV-折叠签名,初始化未知字向量,初始化CNN参数 - 通过保持均匀 在每个数据集内。
Results and Discussion
我们的模型与其他方法的结果列于表2.我们的基准模型与所有随机初始化的单词(CNN-rand)本身并不完美。 虽然我们通过使用预训练的驾驶员来预期性能上的提升,但是我们对增益的幅度感到惊讶。 即使是一个具有静态向量(CNN静态)的简单模型也表现得非常出色,对于采用复杂的池计划(Kalchbrenner et al。,2014)的更复杂的深度学习模型,或提前计算解析树, Socher等,2013)。 这些结果表明,预先训练的矢量是好的,“普遍”的特征提取器,可以跨数据集使用。 对每个任务的预训练矢量进行微调给出了进一步的改进(CNN非静态)。
Multichannel vs. Single Channel Models
我们最初希望多通道架构可以防止过度拟合(通过确保所学习的矢量不会偏离原始值),因此比单通道模型更好,特别是在较小的数据集上。 然而,结果是混合的,并且有必要进一步调整微调过程的正确性。 例如,不是为非静态部分使用附加通道,而是可以保持单个通道,但是需要在训练期间允许修改的额外尺寸。
Static vs. Non-static Representations
与单通道非静态模型的情况一样,多通道模型能够微调非静态通道,使其更具体于手头任务。 例如,良好与word2vec中的差异最相似,大概是因为它们(几乎)在语法上相当。 但是对于在SST-2数据集中进行了微调的非静态通道中的向量,情况就不再这样了(表3)。 同样,好的可以说是更接近于善于表达情感的伟大,这确实体现在学习的向量中。
对于不经过预训练矢量集的(随机初始化)标记,微调使他们能够学习更有意义的表示:网络学习感叹号与流行表达相关联,并且逗号是连接的(表3)。
Further Observations
我们报告一些进一步的实验和观察:
•Kalchbrenner et al。 (2014)报道,CNN的结构与我们的单通道模型基本相同。 例如,具有随机初始化字的Max-TDNN(时间延迟神经网络)在SST-1数据集上获得了37.4%,而我们的模型则为45.0%。 我们将这种差异归因于我们的CNN具有更多的容量(多个滤波器宽度和特征图)。
•辍学被证明是一个很好的正规者,使用更大的必要网络是很好的,只是让辍学正规化。 辍学一直增加了2%-4%的相对性能。
当随机初始化word2vec中的单词时,我们通过从U [-a,a]中抽取每个维度来获得轻微的改进,其中a被选择为使得随机初始化的向量与预先训练的向量具有相同的方差。 有趣的是,如果使用更复杂的方法来反映初始化过程中预先训练的矢量的分布,将进一步改进。
•我们简要地尝试了由Collobert等人训练的另外一组可公开提供的字向量。 (2011)*8,发现word2vec具有更高的性能。 不清楚这是由于Mikolov等人 (2013)的架构或1000亿字Google新闻数据集。
•Adadelta(Zeiler,2012)给出了与Adagrad类似的结果(Duchi et al。,2011),但需要更少的时期。
结论
在目前的工作中,我们已经描述了在word2vec之上构建的卷积神经网络的一系列实验。 尽管很少调整超参数,但是具有一层卷积的简单的CNN执行得非常好。 我们的结果增加了明确的证据,即不受监督的字矢量预训练是NLP深入学习的重要组成部分。
推荐阅读
-
学习笔记:MobileNets: Efficient Convolutional Neural Networks for Mobile Vision
-
Image Style Transfer Using Convolutional Neural Networks
-
吴恩达机器学习作业3:Multi-class Classification and Neural Networks python实现
-
Convolutional Neural Networks for Sentence Classification
-
论文阅读:Convolutional Neural Networks for Sentence Classification
-
CNN for NLP——Convolutional Neural Networks for Sentence Classification
-
Convolutional Neural Networks for Sentence Classification
-
《Convolutional Neural Networks for Sentence Classification》 文本分类
-
Fundamentals of Convolutional Neural Networks
-
Text Classification -- Convolutional Networks、sentence level Attentional RNN、Hierarchical attention