ceph搭建及使用详解
第1章 ceph介绍
1.1 Ceph的主要特点
统一存储
无任何单点故障
数据多份冗余
存储容量可扩展
自动容错及故障自愈
1.2 Ceph三大角色组件及其作用
在Ceph存储集群中,包含了三大角色组件,他们在Ceph存储集群中表现为3个守护进程,分别是Ceph OSD、Monitor、MDS。当然还有其他的功能组件,但是最主要的是这三个。
Ceph OSD
Ceph的OSD(Object Storage Device)守护进程。主要功能包括:存储数据、副本数据处理、数据恢复、数据回补、平衡数据分布,并将数据相关的一些监控信息提供给Ceph Moniter,以便Ceph Moniter来检查其他OSD的心跳状态。一个Ceph OSD存储集群,要求至少两个Ceph OSD,才能有效的保存两份数据。注意,这里的两个Ceph OSD是指运行在两台物理服务器上,并不是在一台物理服务器上运行两个Ceph OSD的守护进程。通常,冗余和高可用性至少需要3个Ceph OSD。
Monitor
Ceph的Monitor守护进程,主要功能是维护集群状态的表组,这个表组中包含了多张表,其中有Moniter map、OSD map、PG(Placement Group) map、CRUSH map。 这些映射是Ceph守护进程之间相互协调的关键簇状态。 监视器还负责管理守护进程和客户端之间的身份验证。 通常需要至少三个监视器来实现冗余和高可用性。
MDS
Ceph的MDS(Metadata Server)守护进程,主要保存的是Ceph文件系统的元数据。注意,对于Ceph的块设备和Ceph对象存储都不需要Ceph MDS守护进程。Ceph MDS为基于POSIX文件系统的用户提供了一些基础命令的执行,比如ls、find等,这样可以很大程度降低Ceph存储集群的压力。
Managers
Ceph的Managers(Ceph Manager),守护进程(ceph-mgr)负责跟踪运行时间指标和Ceph群集的当前状态,包括存储利用率,当前性能指标和系统负载。 Ceph Manager守护程序还托管基于python的插件来管理和公开Ceph集群信息,包括基于Web的仪表板和REST API。 通常,至少有两名Manager需要高可用性。
Ceph的术语表:
http://docs.ceph.com/docs/master/glossary/#term-ceph-storage-cluster
1.3 Ceph的架构及应用场景
文档连接:
http://docs.ceph.com/docs/master/architecture/
Ceph的架构主要分成底层数据分布及上层应用接口,下面是官网架构图:
A library…and PHP #LIBRADOS库允许应用程序可以直接访问Ceph底层的对象存储,它支持的有C、C++、Java、Python、Ruby及PHP语言。
A bucket-based…and Swift #一套基于RESTful协议的网关,并兼容S3和Swift。
A reliable…QEMU/KVM driver #通过Linux内核客户端及QEMU/KVM驱动,来提供一个可靠且完全分布的块设备。
A POSIX-compliant…for FUSE #通过Linux内核客户端结合FUSE,来提供一个兼容POSIX文件结构系统。
A reliable,autonomous…storage nodes #以其具备的自愈功能、自管理、智能存储节点特性,来提供一个可靠、自动、分布式的对象存储。
1.4 RADOS
Ceph的底层核心是RADOS(Reliable, Autonomic Distributed Object Store),Ceph的本质是一个对象存储。RADOS由两个组件组成:OSD和Monitor。OSD主要提供存储资源,每一个disk、SSD、RAID group或者一个分区都可以成为一个OSD,而每个OSD还将负责向该对象的复杂节点分发和恢复;Monitor维护Ceph集群并监控Ceph集群的全局状态,提供一致性的决策。
RADOS分发策略依赖于名为CRUSH(Controlled Replication Under Scalable Hashing)的算法(基于可扩展哈希算法的可控复制)
1.5 应用场景
Ceph的应用场景主要由它的架构确定,Ceph提供对象存储、块存储和文件存储,主要由4种应用:
第一类:LIBRADOS应用
通俗的说,Librados提供了应用程序对RADOS的直接访问,目前Librados已经提供了对C、C++、Java、Python、Ruby和PHP的支持。它支持单个单项的原子操作,如同时更新数据和属性、CAS操作,同时有对象粒度的快照操作。它的实现是基于RADOS的插件API,也就是在RADOS上运行的封装库。
第二类:RADOSGW应用
这类应用基于Librados之上,增加了HTTP协议,提供RESTful接口并且兼容S3、Swfit接口。RADOSGW将Ceph集群作为分布式对象存储,对外提供服务。
第三类:RBD应用
这类应用也是基于Librados之上的,细分为下面两种应用场景。
第一种应用场景为虚拟机提供块设备。通过Librbd可以创建一个块设备(Container),然后通过QEMU/KVM附加到VM上。通过Container和VM的解耦,使得块设备可以被绑定到不同的VM上。
第二种应用场景为主机提供块设备。这种场景是传统意义上的理解的块存储。
以上两种方式都是将一个虚拟的块设备分片存储在RADOS中,都会利用数据条带化提高数据并行传输,都支持块设备的快照、COW(Copy-On-Write)克隆。最重要的是RBD还支持Live migration。
第四类:CephFS(Ceph文件系统)应用
这类应用是基于RADOS实现的PB级分布式文件系统,其中引入MDS(Meta Date Server),它主要为兼容POSIX文件系统提供元数据,比如文件目录和文件元数据。同时MDS会将元数据存储在RADOS中,这样元数据本身也达到了并行化,可以大大加快文件操作的速度。MDS本身不为Client提供数据文件,只为Client提供对元数据的操作。当Client打开一个文件时,会查询并更新MDS相应的元数据(如文件包括的对象信息),然后再根据提供的对象信息直接从RADOS中得到文件数据。**
1.6 本文档没有安装MDS
Ceph 分布式存储集群有三大组件组成,分为:Ceph Monitor、Ceph OSD、Ceph MDS,后边使用对象存储和块存储时,MDS 非必须安装,只有当使用 Cephfs 文件存储时,才需要安装。这里我们暂时不安装 MDS。
1.7 ceph-deploy 常用命令详解
命令 描述
ceph-deploy new [mon-node ...] 指定node(s)为monitor,开始部署一个新的ceph集群,并且在当前目录创建ceph.conf和keyring文件,一共创建了3个文件:ceph.conf、ceph-deploy-ceph.log 和 ceph.mon.keyring. 生成的ceph.conf 文件里包含了命令行的monitor参数,内容为mon_initial_members=[monitor]
ceph-deploy install [host …] 在指定的远程host(admin-node/osd-node/mon-node)上安装Ceph相关的包,如果安装找不到stable 的 ceph 版本,需要手动修改admin-node节点上的/etc/apt/sources.list.d/ceph.list文件
ceph-deploy mon [CMD …] 进行ceph monitor daemon 管理
ceph-deploy mon create-initial 部署并初始化已经定义好的mon_initial_members=[monitor]成员,并等待他们形成仲裁,然后收集密钥keys,会在当前目录下生成几个key,报告进程中monitor的状态。如果monitor不构成仲裁,命令最终将超时。
ceph-deploy osd
使用路径,先prepare 后 activate
prepare [node:/dir …]
从管理节点(admin-node)执行 ceph-deploy 来准备 OSD 。
参数可以是文件或者磁盘,
例如,文件:ceph-deploy osd prepare node1:/var/local/osd0
磁盘:ceph-deploy osd prepare node1:sdb1:sdc
activate [node:/dir …]
激活已经准备好的 OSD。
参数可以是文件或者磁盘,
例如,文件:ceph-deploy osd activate node1:/var/local/osd0
磁盘:ceph-deploy osd activate node1:sdb1:sdc
使用磁盘或者日志,用 `create` 参数将 自动完成prepare 和 activate
create
例1:使用filestore采用journal模式(每个节点数据盘需要两块盘或两个分区)
1)创建逻辑卷.
vgcreate data /dev/sdb
lvcreate --size 00G --name log data
2)创建OSD
ceph-deploy osd create --filestore --fs-type xfs --data /dev/sdc --journal data/log storage1
例2:使用bluestore
1)创建逻辑卷
vgcreate cache /dev/sdb
lvcreate --size 100G --name db-lv-0 cache
vgcreate cache /dev/sdb
lvcreate --size 100G --name wal-lv-0 cache
2)创建OSD
--block-db 对应配置参数:bluestore_block_db_path
--block-wal对应配置参数bluestore_block_wal_path
ceph-deploy osd create --bluestore storage1 --data /dev/sdc --block-db cache/db-lv-0 --block-wal cache/wal-lv-0
ceph-deploy admin [admin- node] [osd-node mon-node …]
把配置文件和 admin 密钥拷贝到管理节点(admin-node)和 Ceph 节点(monitor/osd)的/etc/ceph/目录下
ceph-deploy mgr create [node]
指定node为部署ceph-mgr节点的hostname,并开始mgr 部署。
ceph-deploy disk zap [osd-node]:[disk-name}
擦除指定node的磁盘分区表及其内容,实际上它是调用sgdisk –zap-all来销毁GPT和MBR, 所以磁盘可以被重新分区。可以配合命令ceph-deploy osd prepare/active一起使用
ceph-deploy mds create {host-name}[:{daemon-name}][{host-name}[:{daemon-name}]...]
例如:ceph-deploy --overwrite-conf mds create server1:mds-daemon-1,在server1上创建名为mds-daemon-1的mds后台进程,即server1为CephFS元数据服务器
ceph-deploy --overwrite-conf admin {mon} {osd}
更新mon及osd的ceph.conf配置文件
ceph-deploy --overwrite-conf admin ubuntu-sebre ubuntu
sudo chmod +066 /etc/ceph/ceph.client.admin.keyring
重启服务才能生效 sudo systemctl restart ceph\*.target //重启所有
也可以重启指定的部分sudo systemctl restart ceph-mon.target ceph-osd.target
1.8 ceph命令
命令 描述
ceph -s 查看ceph 集群的状态
ceph df
ceph osd tree
ceph osd pool create {pool-name} {pg-num} [{pgp-num}] [replicated][crush-rule-name] [expected-num-objects]
例如,ceph osd pool create rbd 256,创建名为rbd的ceph pool,等同于命令:rados mkpool pool
通常在创建pool之前,需要覆盖默认的pg_num,官方推荐:
若少于5个OSD, 设置pg_num为128。
5~10个OSD,设置pg_num为512。
10~50个OSD,设置pg_num为4096。
超过50个OSD,可以参考pgcalc计算。
ceph osd pool create {pool-name} {pg-num} {pgp-num} erasure [erasure-code-profile] [crush-rule-name] [expected_num_objects] 同上,提供的是EC容错
ceph osd lspools 查看集群的pools
ceph osd pool ls detail 查看pool的详细信息,例如:ceph> osd pool ls detail pool 14 'rbd' replicated size 1 min_size 1 crush_rule 0 object_hash rjenkins pg_num 128 pgp_num 128 last_change 125 flags hashpspool stripe_width 0
ceph osd pool set {pool-name} size {num} 设置指定pool的副本数为{num}。例如,sudo ceph osd pool set rbd size 1
sudo ceph osd pool set rbd min_size 1
ceph osd pool get {pool-name} size
查看指定pool的副本数,
例如:$ ceph osd pool get rbd size size: 3。
其详细命令:
osd pool get <poolname> size|min_size|crash_replay_interval|pg_num|pgp_num|crush_rule|hashpspool|nodelete|nopgchange| get pool parameter <var>
nosizechange|write_fadvise_dontneed|noscrub|nodeep-scrub|hit_set_type|hit_set_period|hit_set_count|hit_set_fpp|use_
gmt_hitset|auid|target_max_objects|target_max_bytes|cache_target_dirty_ratio|cache_target_dirty_high_ratio|cache_
target_full_ratio|cache_min_flush_age|cache_min_evict_age|erasure_code_profile|min_read_recency_for_promote|all|min_
write_recency_for_promote|fast_read|hit_set_grade_decay_rate|hit_set_search_last_n|scrub_min_interval|scrub_max_
interval|deep_scrub_interval|recovery_priority|recovery_op_priority|scrub_priority|compression_mode|compression_
algorithm|compression_required_ratio|compression_max_blob_size|compression_min_blob_size|csum_type|csum_min_block|
csum_max_block|allow_ec_overwrites
ceph osd pool delete {pool-name} {pool-name} --yes-i-really-really-mean-it
删除某个pool,需要配置/etc/ceph/ceph.conf的[mon] mon allow pool delete = true。
然后重启ceph mon,命令:sudo systemctl restart ceph-mon.target
再删除命令,ceph osd pool delete rbd rbd --yes-i-really-really-mean-it
ceph osd dump | grep 'replicated size'
查看OSD日志,例如:$ceph osd dump | grep 'replicated size'
pool 9 'rbd' replicated size 1 min_size 1 crush_rule 0 object_hash rjenkins pg_num 100 pgp_num 100 last_change 68 flags hashpspool stripe_width 0
ceph osd set noscrub
设置不做scrub一致性检查,防止影响性能。设置不做深度scrub检查:ceph osd set nodeep-scrub
ceph osd getcrushmap -o {compiled-crushmap-filename}
将集群的CRUSH Map输出到指定文件,该文件是编译过的文件
crushtool -d {compiled-crushmap-filename} -o {decompiled-crushmap-filename}
反编译集群里导出的 CRUSH Map 文件,反编译后为文本文件
crushtool -c {decompiled-crushmap-filename} -o {compiled-crushmap-filename}
编译 CRUSH Map 文本文件
ceph -n {nodename.id} –show-config
显示当前的ceph节点的配置,可以指定某个节点,例如:
ceph -n osd.0 --show-config
ceph -n mon.node1 --show-config
ceph mds stat
查看CephFS元数据服务器运行状态
ceph fs new <fs_name> <metadata_pool> <data_pool>
用指定的元数据池和数据池新建一个CephFS文件系统
ceph fs ls
查看cephfs列表,$ sudo ceph fs ls
name: test_cephfs1, metadata pool: cephfs_metadata, data pools: [cephfs_data ]
ceph daemon <mon/osd/mds>.<id> config set <参数名> <参数值>
动态调整参数命令,只能在本地设置本地实例的参数
ceph tell <mon/osd/mds>.<id> injectargs '--<参数名> <参数值>'
动态调整参数命令,可以通过'*'的方式设置所有的实例的参数
参考:
http://docs.ceph.com/docs/master/rados/operations/pools/
1.9 ceph-conf命令
命令 描述
ceph-conf --name mon.node1 --show-config-value log_file
查看ceph monitor 的日志路径。
例如:~$ ceph-conf --name mon.node1 --show-config-value log_file
/var/log/ceph/ceph-mon.node1.log。
其实monitor节点的/var/log/ceph/目录下有很多类型的log,ceph-mgr、ceph-mon、ceph、ceph-client、ceph.audit
ceph-conf --name osd.0 --show-config-value log_file \
查看ceph osd 的日志路径
1.10 rados命令
命令 描述
rados lspools 查看ceph 集群的pool
rados mkpool <pool-name> 创建名为<pool-name>的ceph pool
rados ls 列出叫rbd的pool里的objects
1.11 rbd命令
命令 描述
rbd create image1 --size 60G
默认在rbd pool下创建一个名为image1, 大小为1G的image,等同于
rbd create rbd/image1 --size 60G --image-format 2
rbd list
列出所有的块设备image
rbd info image1
查看某个具体的image的信息。例如:
$ rbd info image1
rbd image 'image1':
size 1GiB in 256 objects
order 22 (4MiB objects)
block_name_prefix: rbd_data.10356b8b4567
format: 2
features: layering, exclusive-lock, object-map, fast-diff, deep-flatten
flags:
create_timestamp: Wed Jun 19 16:05:40 2019
rbd feature disable image1 exclusive-lock, object-map, fast-diff, deep-flatten
关掉image1的一些feature
rbd map image1
把test_image块设备映射到操作系统,
例如:h$ sudo rbd map image1
/dev/rbd0
rbd showmapped
显示已经映射的块设备,
例如:$ rbd showmapped
id pool image snap device
0 rbd image1 - /dev/rbd0
rbd unmap image1 取消映射
rbd rm image 删除一个rbd image
参考网址
https://blog.csdn.net/don_chiang709/article/details/91952060
第2章 搭建ceph
2.1 中文官网地址
http://docs.ceph.org.cn/start/quick-start-preflight/
2.2 环境
Centos 7系列
本文档环境
CentOS Linux release 7.6.1810 (Core)
2.3 ceph-deploy版本
ceph-deploy --version
1.5.39
2.4 主机要求
3台服务器(1核cpu,2G内存,新加一块20G的磁盘)
2.5 修改主机名
#在对应的主机上操作
hostnamectl set-hostname ceph01
hostnamectl set-hostname ceph02
hostnamectl set-hostname ceph03
2.6 关闭防火墙和selinux
所有节点
systemctl disable firewalld
systemctl stop firewalld
setenforce 0
2.7 修改主机名解析
#ceph01节点操作,然后复制到其他节点
cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.56.4 ceph01
192.168.56.5 ceph02
192.168.56.6 ceph03
#复制主机名解析文件到其他节点
scp /etc/hosts ceph02:/etc/
scp /etc/hosts ceph03:/etc/
2.8 安装授时服务
#在所有节点安装配置chrony
yum -y install chrony
vim /etc/chrony.conf
server ntp1.aliyun.com iburst
systemctl enable chronyd
systemctl restart chronyd
2.9 安装epel源
Ceph 提供了部署工具 ceph-deploy 来方便安装 Ceph 集群,我们只需要在 ceph-deploy 节点上安装即可,这里对应的就是 ceph01 节点。把 Ceph 仓库添加到 ceph-deploy 管理节点,然后安装 ceph-deploy。
yum install -y yum-utils && yum-config-manager --add-repo https://dl.fedoraproject.org/pub/epel/7/x86_64/ && yum install --nogpgcheck -y epel-release && rpm --import /etc/pki/rpm-gpg/RPM-GPG-KEY-EPEL-7 && rm /etc/yum.repos.d/dl.fedoraproject.org*
2.10 配置yum源
需要特别注意的是,Ceph的安装过程还需要第三方组件依赖,其中一些第三方组件在CentOS yum.repo Base等官方源中是没有的(例如LevelDB),所以读者在安装过程中会有一定的几率遇到各种依赖关系异常,并要求先行安装XXX第三方组件的提示(例如提示先安装liblevel.so)。虽然我们后文将会介绍的Ceph辅助部署工具,Ceph-deploy的工作本质还是通过yum命令去安装管理组件,但是既然CentOS yum.repo Base官方源中并没有某些需要依赖的第三方组件,所以一旦遇到类似的组件依赖问题安装过程就没法自动继续了。解决这个问题,本示例中建议引入CentOS的第三方扩展源epel。(我在这上面坑了很久才走出来)。#在每个节点都执行
首先引入第三方扩展源:
wget -O /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo
2.11 添加官网的ceph源
#在每个节点都执行
cat> /etc/yum.repos.d/ceph.repo<<eof
[Ceph]
name=Ceph packages for $basearch
baseurl=http://download.ceph.com/rpm-jewel/el7/$basearch
enabled=1
gpgcheck=1
type=rpm-md
gpgkey=https://download.ceph.com/keys/release.asc
priority=1
[Ceph-noarch]
name=Ceph noarch packages
baseurl=http://download.ceph.com/rpm-jewel/el7/noarch
enabled=1
gpgcheck=1
type=rpm-md
gpgkey=https://download.ceph.com/keys/release.asc
priority=1
[ceph-source]
name=Ceph source packages
baseurl=http://download.ceph.com/rpm-jewel/el7/SRPMS
enabled=1
gpgcheck=1
type=rpm-md
gpgkey=https://download.ceph.com/keys/release.asc
priority=1
eof
说明:baseurl中的rpm-jewel为ceph版本。这个源很慢,可以用阿里云的源替换。
yum clean all && yum makecache
2.12 添加阿里云的ceph源
#在每个节点都执行
cat >/etc/yum.repos.d/ceph.repo<<eof
[Ceph-SRPMS]
name=Ceph SRPMS packages
baseurl=https://mirrors.aliyun.com/ceph/rpm-jewel/el7/SRPMS/
enabled=1
gpgcheck=0
type=rpm-md
[Ceph-aarch64]
name=Ceph aarch64 packages
baseurl=https://mirrors.aliyun.com/ceph/rpm-jewel/el7/aarch64/
enabled=1
gpgcheck=0
type=rpm-md
[Ceph-noarch]
name=Ceph noarch packages
baseurl=https://mirrors.aliyun.com/ceph/rpm-jewel/el7/noarch/
enabled=1
gpgcheck=0
type=rpm-md
[Ceph-x86_64]
name=Ceph x86_64 packages
baseurl=https://mirrors.aliyun.com/ceph/rpm-jewel/el7/x86_64/
enabled=1
gpgcheck=0
type=rpm-md
eof
yum clean all && yum makecache
2.13 添加网易的ceph源
#在每个节点都执行
cat> /etc/yum.repos.d/ceph.repo <<eof
[Ceph]
name=Ceph packages for $basearch
baseurl=http:// mirrors.163.com/ceph /rpm-jewel/el7/$basearch
enabled=1
gpgcheck=1
type=rpm-md
gpgkey=https:// mirrors.163.com/ceph /keys/release.asc
priority=1
[Ceph-noarch]
name=Ceph noarch packages
baseurl=http:// mirrors.163.com/ceph /rpm-jewel/el7/noarch
enabled=1
gpgcheck=1
type=rpm-md
gpgkey=https:// mirrors.163.com/ceph /keys/release.asc
priority=1
[ceph-source]
name=Ceph source packages
baseurl=http:// mirrors.163.com/ceph /rpm-jewel/el7/SRPMS
enabled=1
gpgcheck=1
type=rpm-md
gpgkey=https:// mirrors.163.com/ceph /keys/release.asc
priority=1
eof
yum clean all && yum makecache
2.14 安装ceph-deploy及相关工具
#ceph01节点执行
yum update && yum install ceph-deploy
2.15 创建部署ceph的用户
注意用户名不能是ceph
所有节点操作
useradd -d /home/cephd -m cephd
passwd cephd
确保各节点上新创建的用户都有 sudo 权限。
echo "cephd ALL = (root) NOPASSWD:ALL" | sudo tee /etc/sudoers.d/cephd
chmod 0440 /etc/sudoers.d/cephd
2.16 允许cephd无密码 SSH 登录
正因为 ceph-deploy 不支持输入密码,你必须在管理节点上生成 SSH 密钥并把其公钥分发到各 Ceph 节点。 ceph-deploy 会尝试给初始 monitors 生成 SSH 密钥对。
生成 SSH 密钥对,但不要用 sudo 或 root 用户。提示 “Enter passphrase” 时,直接回车,口令即为空:
su - cephd
ssh-keygen #一直回车
#把公钥拷贝到各 Ceph 节点
ssh-copy-id cephd@ceph01
ssh-copy-id cephd@ceph02
ssh-copy-id cephd@ceph03
2.17 修改/home/cephd/.ssh/config文件
这个文件是新建的
这样 ceph-deploy 就能用你所建的用户名登录 Ceph 节点了,而无需每次执行 ceph-deploy 都要指定 --username {username} 。这样做同时也简化了 ssh 和 scp 的用法。把 {username} 替换成你创建的用户名。
cat >/home/cephd/.ssh/config <<eof
Host ceph01
Hostname ceph01
User cephd
Host ceph02
Hostname ceph02
User cephd
Host ceph03
Hostname ceph03
User cephd
eof
#授权
chmod 600 /home/cephd/.ssh/config
2.18 开放所需端口
Ceph Monitors 之间默认使用 6789 端口通信, OSD 之间默认用 6800:7300 这个范围内的端口通信。详情见网络配置参考http://docs.ceph.org.cn/rados/configuration/network-config-ref/。 Ceph OSD 能利用多个网络连接进行与客户端、monitors、其他 OSD 间的复制和心跳的通信。
某些发行版(如 RHEL )的默认防火墙配置非常严格,你可能需要调整防火墙,允许相应的入站请求,这样客户端才能与 Ceph 节点上的守护进程通信。
对于 RHEL 7 上的 firewalld ,要对公共域开放 Ceph Monitors 使用的 6789 端口和 OSD 使用的 6800:7300 端口范围,并且要配置为永久规则,这样重启后规则仍有效。例如:
sudo firewall-cmd --zone=public --add-port=6789/tcp --permanent
若使用 iptables ,要开放 Ceph Monitors 使用的 6789 端口和 OSD 使用的 6800:7300 端口范围,命令如下:
sudo iptables -A INPUT -i {iface} -p tcp -s {ip-address}/{netmask} --dport 6789 -j ACCEPT
在每个节点上配置好 iptables 之后要一定要保存,这样重启之后才依然有效。例如:
/sbin/service iptables save
2.19 创建执行目录
#ceph01节点操作
su - cephd
mkdir /home/cephd/ceph-cluster && cd /home/cephd/ceph-cluster
2.20 创建集群
#ceph01节点操作
su - cephd
cd /home/cephd/ceph-cluster
sudo ceph-deploy new ceph01 ceph02 ceph03 #多个mon节点 集群方式
此时,我们会发现 ceph-deploy 会在 ceph-cluster 目录下生成几个文件,ceph.conf 为 ceph 配置文件,ceph-deploy-ceph.log 为 ceph-deploy 日志文件,ceph.mon.keyring 为 ceph monitor 的密钥环。
把 Ceph 配置文件里的默认副本数从 3 改成 2 ,这样只有两个 OSD 也可以达到 active + clean 状态。把下面这行加入 [global] 段:
修改下 ceph.conf 配置文件,增加副本数为 2。
增加如下配置
sudo vim /home/cephd/ceph-cluster/ceph.conf
osd pool default size = 2 #增加默认副本数为 2
如果你有多个网卡,可以把 public network 写入 Ceph 配置文件的 [global] 段下。详情见
http://docs.ceph.org.cn/rados/configuration/network-config-ref/
官网建议使用xfs格式化硬盘作为ceph的osd存储数据的目录,这里用的是ext4格式化的,所以要加如下配置,否则会报错。
osd max object name len = 256
osd max object namespace len = 64
2.21 安装 ceph
#ceph01节点操作
su - cephd
cd /home/cephd/ceph-cluster
sudo ceph-deploy install ceph01 ceph02 ceph03
2.23 初始化mon节点并收集所有秘钥
#ceph01节点操作
ceph-deploy mon create-initial
完成上述操作后,当前目录里应该会出现这些密钥环:
ceph.bootstrap-mds.keyring
ceph.bootstrap-mgr.keyring
ceph.bootstrap-osd.keyring
ceph.bootstrap-rgw.keyring
ceph.client.admin.keyring
2.24 查看ceph集群状态
第3章 硬盘添加osd
3.1 添加osd节点
#接下来需要创建 OSD 了,OSD 是最终数据存储的地方,这里我们准备了3个 OSD 节点。官方建议为 OSD 及其日志使用独立硬盘或分区作为存储空间,也可以使用目录的方式创建。
#给node01,node02,node03 分别添加一块20G硬盘,创建分区/dev/sdb1,格式化为ext4 文件系统
#每个节点都执行
fdisk /dev/sdb #这里根据情况执行,不一定是/dev/sdb
mkfs.xfs /dev/sdb1
chown -R ceph:ceph /dev/sdb1
mkdir /osd
3.2 准备OSD
#ceph01节点操作执行 prepare OSD 操作,目的是分别在各个 OSD 节点上创建一些后边激活 OSD 需要的信息。
cd /home/cephd/ceph-cluster/
ceph-deploy --overwrite-conf osd prepare ceph01:/osd ceph02:/osd ceph03:/osd
3.3 激活OSD
#ceph01节点操作
cd /home/cephd/ceph-cluster/
chown -R ceph.ceph /osd/
ceph-deploy osd activate ceph01:/osd ceph02:/osd ceph03:/osd
注意:目录不能是/home
#node02和node03操作
授权osd挂载目录,这里是/osd/
chown -R ceph.ceph /osd/
3.4 查看ceph集群状态
第4章 分发配置文件
用 ceph-deploy 把配置文件和 admin 密钥拷贝到管理节点和 Ceph 节点,这样你每次执行 Ceph 命令行时就无需指定 monitor 地址和 ceph.client.admin.keyring 了。
#ceph01节点执行
ceph-deploy admin ceph01 ceph02 ceph03
4.1 授权
#ceph01,ceph02,ceph03节点操作
chmod +r /etc/ceph/ceph.client.admin.keyring
4.2 集群健康监测
ceph health
HEALTH_OK #这是正确输出
第5章 报错及解决
5.1 创建集群遇到的问题及解决
sudo ceph-deploy new ceph01 ceph02 ceph03遇到的问题及解决方法如下
遇到的问题1
ceph-deploy new ceph01
Traceback (most recent call last):
File "/bin/ceph-deploy", line 5, in <module>
from pkg_resources import load_entry_point
ImportError: No module named pkg_resources
解决:
重新安装python的distribution:
下载 distribution : https://pypi.python.org/pypi/distribute
cd distribution-0.7.3/
sudo python setup.py install
distribution下载地址:
https://files.pythonhosted.org/packages/5f/ad/1fde06877a8d7d5c9b60eff7de2d452f639916ae1d48f0b8f97bf97e570a/distribute-0.7.3.zip
遇到的问题2
sudo ceph-deploy new ceph01
[ceph_deploy.conf][DEBUG ] found configuration file at: /root/.cephdeploy.conf
[ceph_deploy.cli][INFO ] Invoked (1.5.25): /bin/ceph-deploy new ceph01
[ceph_deploy.new][DEBUG ] Creating new cluster named ceph
[ceph_deploy.new][INFO ] making sure passwordless SSH succeeds
[ceph_deploy][ERROR ] Traceback (most recent call last):
[ceph_deploy][ERROR ] File "/usr/lib/python2.7/site-packages/ceph_deploy/util/decorators.py", line 69, in newfunc
[ceph_deploy][ERROR ] return f(*a, **kw)
[ceph_deploy][ERROR ] File "/usr/lib/python2.7/site-packages/ceph_deploy/cli.py", line 162, in _main
[ceph_deploy][ERROR ] return args.func(args)
[ceph_deploy][ERROR ] File "/usr/lib/python2.7/site-packages/ceph_deploy/new.py", line 141, in new
[ceph_deploy][ERROR ] ssh_copy_keys(host, args.username)
[ceph_deploy][ERROR ] File "/usr/lib/python2.7/site-packages/ceph_deploy/new.py", line 35, in ssh_copy_keys
[ceph_deploy][ERROR ] if ssh.can_connect_passwordless(hostname):
[ceph_deploy][ERROR ] File "/usr/lib/python2.7/site-packages/ceph_deploy/util/ssh.py", line 15, in can_connect_passwordless
[ceph_deploy][ERROR ] if not remoto.connection.needs_ssh(hostname):
[ceph_deploy][ERROR ] AttributeError: 'module' object has no attribute 'needs_ssh'
[ceph_deploy][ERROR ]
问题原因:和ceph-deploy版本有关系ceph-deploy.noarch 0:1.5.25-1.el7版本会报这个问题,即使把这个问题按照如下方法解决了,执行sudo ceph-deploy install ceph01 ceph02 ceph03还会报其他错误,所以根本解决方法是更换ceph-deploy版本
解决:
sudo ceph-deploy new ceph01 --no-ssh-copykey
遇到的问题3
CentOS 7 quick start fails with RuntimeError: NoSectionError: No section: ‘ceph’
解决:
sudo mv /etc/yum.repos.d/ceph.repo /etc/yum.repos.d/ceph-deploy.repo
RuntimeError: connecting to host: node03 resulted in errors: IOError cannot send (already closed?)
解决:
sudo:抱歉,您必须拥有一个终端来执行 sudo
解决
所有节点执行
将/etc/sudoers文件中的下面那行注释掉
Defaults requiretty
遇到的问题4
[ceph01][ERROR ] RuntimeError: command returned non-zero exit status: 1
[ceph_deploy][ERROR ] RuntimeError: Failed to execute command: yum -y install epel-release
解决:
进入/etc/yum.repos.d中删除epel.repo和epel-testing.repo
5.2 安装ceph遇到的问题及解决
执行sudo ceph-deploy install ceph01 ceph02 ceph03遇到的问题及解决方法如下
遇到的问题1
[ceph_deploy][ERROR ] RuntimeError: NoSectionError: No section: 'ceph'
解决:
sudo yum remove ceph-release
5.3 初始化mon报错及解决
执行ceph-deploy mon create-initial遇到的问题及解决方法如下
遇到的问题1
ERROR ] RuntimeError: config file /etc/ceph/ceph.conf exists with different content; use --overwrite-conf to overwrite
[ceph_deploy][ERROR ] GenericError: Failed to create 1 monitors
解决:
ceph-deploy --overwrite-conf mon create-initial
到此,ceph monitor 已经成功启动了。
5.4 检查集群状态报错及解决
ceph -s
2019-09-22 20:28:34.888971 7f5272f01700 -1 auth: unable to find a keyring on /etc/ceph/ceph.client.admin.keyring,/etc/ceph/ceph.keyring,/etc/ceph/keyring,/etc/ceph/keyring.bin: (2) No such file or directory
2019-09-22 20:28:34.888987 7f5272f01700 -1 monclient(hunting): ERROR: missing keyring, cannot use cephx for authentication
2019-09-22 20:28:34.888989 7f5272f01700 0 librados: client.admin initialization error (2) No such file or directory
Error connecting to cluster: ObjectNotFound
解决
sudo ln -s /home/cephd/ceph-cluster/ceph.client.admin.keyring /etc/ceph/
5.5 ceph安装时报错RuntimeError: NoSectionError
安装ceph时出错
[ceph_deploy][ERROR ] RuntimeError: NoSectionError: No section: 'ceph'
解决办法:
yum remove ceph-release
把这个东西卸了,应该是这个的版本不兼容 亲测有效。
第6章 操作集群
6.1 ceph相关服务
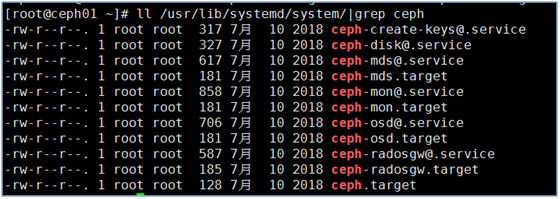
ll /usr/lib/systemd/system/|grep cep
-rw-r–r-- 1 root root 317 7月 10 2018 ceph-create-keys@.service
-rw-r–r-- 1 root root 327 7月 10 2018 ceph-disk@.service
-rw-r–r-- 1 root root 617 7月 10 2018 ceph-mds@.service
-rw-r–r-- 1 root root 181 7月 10 2018 ceph-mds.target
-rw-r–r-- 1 root root 858 7月 10 2018 ceph-mon@.service
-rw-r–r-- 1 root root 181 7月 10 2018 ceph-mon.target
-rw-r–r-- 1 root root 706 7月 10 2018 ceph-osd@.service
-rw-r–r-- 1 root root 181 7月 10 2018 ceph-osd.target
-rw-r–r-- 1 root root 128 7月 10 2018 ceph.target
## 6.2 清除集群
如果在某些地方碰到麻烦,想从头再来,可以用下列命令清除配置:
ceph-deploy purgedata {ceph-node} [{ceph-node}]
ceph-deploy forgetkeys
用下列命令可以连 Ceph 安装包一起清除:
ceph-deploy purge {ceph-node} [{ceph-node}]
如果执行了 purge ,你必须重新安装 Ceph 。
## 6.3 添加osd
这里把目录而非整个硬盘用于 OSD 守护进程
登录到 Ceph 节点、并给 OSD 守护进程创建一个目录。
#在ceph01节点执行
mkdir /var/local/osd1 -p
准备 OSD
ceph-deploy osd prepare ceph01:/var/local/osd1
chown -R ceph.ceph /var/local/osd1/ #不授权会报错
激活OSD
ceph-deploy osd activate ceph01:/var/local/osd1
一旦你新加了 OSD , Ceph 集群就开始重均衡,把归置组迁移到新 OSD 。可以用下面的 ceph 命令观察此过程:
ceph -w
## 6.4 添加元数据服务器
至少需要一个元数据服务器才能使用 CephFS ,执行下列命令创建元数据服务器:
#在ceph01节点执行,这里选择在ceph01添加。
ceph-deploy mds create ceph01
当前生产环境下的 Ceph 只能运行一个元数据服务器。你可以配置多个,但现在我们还不会为多个元数据服务器的集群提供商业支持。
## 6.5 添加 MONITORS
Ceph 存储集群需要至少一个 Monitor 才能运行。为达到高可用,典型的 Ceph 存储集群会运行多个 Monitors,这样在单个 Monitor 失败时不会影响 Ceph 存储集群的可用性。Ceph 使用 PASOX 算法,此算法要求有多半 monitors(即 1 、 2:3 、 3:4 、 3:5 、 4:6 等 )形成法定人数。
新增两个监视器到 Ceph 集群。
ceph-deploy mon add ceph02

public network是公共网络,是osd之间通信的网络,该项建议设置,如果不设置,后面可能执行命令的时候有警告信息,该参数其实就是你的mon节点IP最后一项改为0,然后加上/24。
解决:
vim /home/cephd/ceph-cluster/ceph.conf
public network = 192.168.56.0/24
ceph-deploy --overwrite-conf config push ceph02
不推送直接执行ceph-deploy mon add ceph02会报错如下

推送过去的配置存在节点的/etc/ceph/ceph.conf目录下
## 6.6 推送配置
在有ceph-deploy改完配置后推送到各个节点
ceph-deploy --overwrite-conf config push {node主机名}
## 6.7 添加 RGW 例程
要使用 Ceph 的 Ceph 对象网关组件,必须部署 RGW 例程。用下列方法创建新 RGW 例程:
yum -y install ceph-radosgw
ceph-deploy rgw create ceph01
注意:这个功能是从 Hammer 版和 ceph-deploy v1.5.23 才开始有的。
RGW 例程默认会监听 7480 端口,可以更改该节点 ceph.conf 内与 RGW 相关的配置,如下:
[client]
rgw frontends = civetweb port=80
用的是 IPv6 地址的话:
[client]
rgw frontends = civetweb port=[::]:80
推送配置
ceph-deploy --overwrite-conf config push ceph01
## 6.8 ceph osd 删除
一般情况下,osd 是不需要进行删除操作的,但是凡事无绝对;很多时候还是需要进行删除操作(例如,对已经部署好的存储集群重新进行方案的调整,就需要对osd进行删除操作,重新进行调整)
#查看需要删除的osd的id
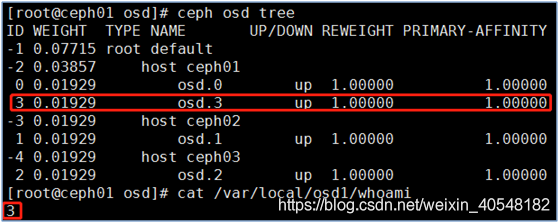
#将osd out
#reweight 会被置为 0,集群会进行数据迁移,相当于进行 "ceph osd reweight <osdname (id|osd.id)> <float[0.0-1.0]>" 操作,当 "reweight" 为 0 时,该 osd节点 不纳入 "in" 计数。
ceph osd out {osd_id}
#关闭 osd节点的守护进程,在关闭守护进程之前,需要等待 out 之后的数据迁移结束,该节点的守护进程不纳入 "up" 计数。
systemctl stop ceph-osd@{osd_id}.service
#remove osd,weight 变为 0,则会更改 crush 算法的权重
ceph osd crush remove osd.{osd_id}
#aut del osd,删除 osd 节点相关的权限信息
ceph auth del osd.{osd_id}
#rm osd,删除 osd 节点 id号
ceph osd rm {osd_id}
## 第7章 ceph命令详解
## 7.1 集群管理
ceph –s 检查集群状况
ceph health 集群健康状态检查
## 7.2 存储管理
ceph df 查看存储使用情况
ceph osd pool ls 查看存储池
ceph osd pool create volumes 128 创建存储池
ceph osd pool delete 存储池名字 --yes-i-really-really-mean-it 删除存储池,删除存储池需要先改配置文件,改完后重启mon服务
cat /etc/ceph/ceph.conf
[mon] #添加配置
mon_allow_pool_delete = true
systemctl restart ceph-mon@serverce 重启monitor服务
systemctl restart ceph-mon.target 重启monitor服务
说明:centos7系统,系统的启动文件放在/usr/lib/systemd/system/目录下,如果不确定进程的名字,可以ll /usr/lib/systemd/system/|grep ceph查看
## 7.3 Ceph用户管理
Ceph授权
Ceph把数据以对象的形式存于个存储池中,Ceph用户必须具有访问存储池的权限能够读写数据
Ceph用caps来描述给用户的授权,这样才能使用Mon,OSD和MDS的功能
caps也用于限制对某一存储池内的数据或某个命名空间的访问
Ceph管理用户可在创建或更新普通用户是赋予其相应的caps
Ceph常用权限说明:
r:赋予用户读数据的权限,如果我们需要访问集群的任何信息,都需要先具有monitor的读权限
w:赋予用户写数据的权限,如果需要在osd上存储或修改数据就需要为OSD授予写权限
x:赋予用户调用对象方法的权限,包括读和写,以及在monitor上执行用户身份验证的权限
class-read:x的子集,允许用户调用类的read方法,通常用于rbd类型的池
class-write:x的子集,允许用户调用类的write方法,通常用于rbd类型的池
*:将一个指定存储池的完整权限(r、w和x)以及执行管理命令的权限授予用户
profile osd:授权一个用户以OSD身份连接其它OSD或者Monitor,用于OSD心跳和状态报告
profile mds:授权一个用户以MDS身份连接其他MDS或者Monitor
profile bootstrap-osd:允许用户引导OSD。比如ceph-deploy和ceph-disk工具都使用client.bootstrap-osd用户,该用户有权给OSD添加密钥和启动加载程序
profile bootstrap-mds:允许用户引导MDS。比如ceph-deploy工具使用了client.bootstrap-mds用户,该用户有权给MDS添加密钥和启动加载程序
创建用户
ceph auth add client.ning mon ‘allow r’ osd ‘allow rw pool=testpool’ #当用户不存在,则创建用户并授权;当用户存在,当权限不变,则不进行任何输出;当用户存在,不支持修改权限
参数说明:
client.ning 用户名字
mon ‘allow r’ 容许读mon
osd ‘allow rw pool=testpool’ 容许读写osd的testpool存储池
ceph auth get-or-create client.joy mon ‘allow r’ osd ‘allow rw pool=mytestpool’ #当用户不存在,则创建用户并授权并返回用户和key,当用户存在,权限不变,返回用户和key,当用户存在,权限修改,则返回报错
删除用户
ceph auth del client.xxx #删除xxx用户
导出用户
ceph auth get-or-create client.ning -o ./ceph.client.ning.keyring
导入用户
ceph auth export client.ning -o /etc/ceph/ceph.client.ning-1.keyring
查看用户权限
ceph auth get client.joy
添加用户权限
ceph auth caps client.joy mon ‘allow r’ osd ‘allow rw pool=mytestpool,allow rw pool=testpool’ #对用户joy添加对testpool这个池的权限
推送用户
创建的用户主要用于客户端授权,所以需要将创建的用户推送至客户端。如果需要向同一个客户端推送多个用户,可以将多个用户的信息写入同一个文件,然后直接推送该文件
ceph-authtool -C /etc/ceph/ceph.keyring #创建一个秘钥文件
creating /etc/ceph/ceph.keyring
ceph-authtool ceph.keyring --import-keyring ceph.client.ning.keyring #把用户client.ning添加进秘钥文件
importing contents of ceph.client.ning.keyring into ceph.keyring
cat ceph.keyring #查看
[client.ning]
key = AQAcBY5coY/rLxAAvq99xcSOrwLI1ip0WAw2Sw==
ceph-authtool ceph.keyring --import-keyring ceph.client.joy.keyring #把用户client.ning添加进秘钥文件
importing contents of ceph.client.joy.keyring into ceph.keyring
cat ceph.keyring #查看有两个用户,可以把这文件推送给客户端,就可以使用这两个用户的权限
[client.joy]
key = AQBiBY5cJ2gBLBAA/ZCGDdp6JWkPuuU0YaLsrw==
[client.ning]
key = AQAcBY5coY/rLxAAvq99xcSOrwLI1ip0WAw2Sw==
用户被删除,恢复用户
cat ceph.client.ning.keyring #秘钥环没有权限信息
[client.ning]
key = AQAcBY5coY/rLxAAvq99xcSOrwLI1ip0WAw2Sw==
ceph auth del client.ning #删除这个用户
updated
ll /etc/ceph/ceph.client.ning.keyring #在客户端,秘钥环依然存在
-rw-r–r-- 1 root root 62 Mar 17 16:40 /etc/ceph/ceph.client.ning.keyring
ceph -s --name client.ning #秘钥环的用户被删除,无效
2019-03-17 17:49:13.896609 7f841eb27700 0 librados: client.ning authentication error (1) Operation not permitted
[errno 1] error connecting to the cluster
ceph auth import -i ./ceph.client.ning-1.keyring #使用ning-1.keyring恢复
imported keyring
ceph auth list |grep ning #用户恢复
installed auth entries:
client.ning
ceph osd pool ls --name client.ning #客户端验证,秘钥生效
testpool
EC-pool
本文地址:https://blog.csdn.net/weixin_40548182/article/details/108862031