Fuxi2.0—飞天大数据平台调度系统全面升级,首次亮相2019双十一 框架
程序员文章站
2023-12-21 15:40:52
...
伏羲(Fuxi)是十年前创立飞天平台时的三大服务之一(分布式存储 Pangu,分布式计算 ODPS,分布式调度 Fuxi),当时的设计初衷是为了解决大规模分布式资源的调度问题(本质上是多目标的最优匹配问题)。
随着阿里经济体和阿里云业务需求(尤其是双十一)的不断丰富,伏羲的内涵也不断扩大,从单一的资源调度器(对标开源系统的YARN)扩展成大数据的核心调度服务,覆盖数据调度(Data Placement)、资源调度(Resouce Management)、计算调度(Application Manager)、和本地微(自治)调度等多个领域,并在每一个细分领域致力于打造超越业界主流的差异化能力。
过去十年来,伏羲在技术能力上每年都有新的进展和突破,2013年5K,2015年Sortbenchmark世界冠军,2017年超大规模离在/在离线混部能力,2019年的 Yugong 发布并且论文被VLDB2019接受等。随着 Fuxi 2.0 首次亮相2019双11,今年飞天大数据平台在混部侧支持和基线保障2个方面均顺利完成了目标。其中,混部支持了双十一 60%在线交易洪峰的流量,超大规模混部调度符合预期。在基线保障方面,单日数据处理 970PB,较去年增长超过60%。在千万级别的作业上,不需要用户额外调优,基本做到了无人工干预的系统自动化。
新的挑战
====
随着业务和数据的持续高速增长,MaxCompute 双十一的作业量和计算数据量每年的增速都保持在60%以上 。
2019双十一,MaxCompute 日计算数据量规模已接近EB级,作业量也到了千万量级,在如此大规模和资源紧张的情况下,要确保双十一稳定运行,所有重要基线作业按时产出压力相当之大。
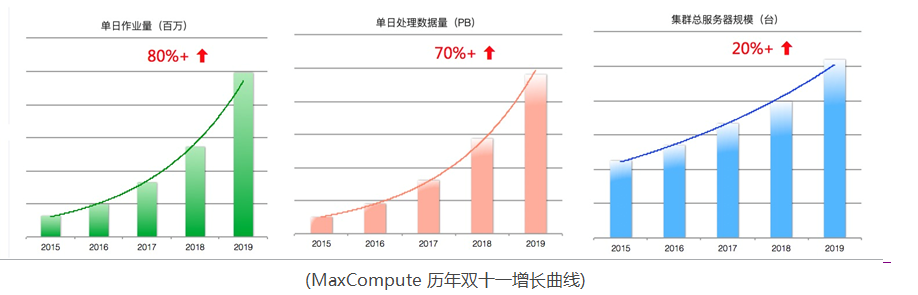
**在双十一独特的大促场景下,2019双11的挑战主要来自以下几个方面:**
1. 超大规模计算场景下,以及资源紧张的情况下,如何进一步提升平台的整体性能,来应对业务的持续高速增长。
2. 双十一会给MaxCompute带来全方面超压力的极端场景,如几亿条的热点key、上千倍的数据膨胀等,这对集群磁盘IO的稳定性、数据文件读写性能、长尾作业重跑等各方面都是挑战。
3. 近千万量级作业的规模下,如何做到敏捷、可靠、高效的分布式作业调度执行。
4. 以及对高优先级作业(如重要业务基线)的资源保障手段。
5. 今年也是云上集群首次参与双十一,并且开始支持混部。
如何应对挑战
======
为了应对上述挑战,与往年相比,除了常规的HBO等调整之外,飞天大数据平台加速了过去1-2年中技术积累成果的上线,尤其是 **Fuxi 2.0 首次亮相双十一**,最终在单日任务量近千万、单日计算量近千PB的压力下,保障了基线全部按时产出。
* 在平台性能优化方面,对于挑战#1和#2,**StreamlineX + Shuffle Service** 根据实时数据特征自动智能化匹配高效的处理模式和算法,挖掘硬件特性深度优化IO,内存,CPU等处理效率,在减少资源使用的同时,**让全量SQL平均处理速度提升将近20%**,出错重试率下降至原来的几十分之一,大大提了升MaxCompute 平台整体效能。
* 在分布式作业调度执行方面,对于挑战#3,**DAG 2.0 **提供了更敏捷的调度执行能力,和全面去阻塞能力,能为大规模的MR作业带来**近50%的性能提升**。同时DAG动态框架的升级,也为分布式作业的调度执行带来了更灵活的动态能力,能根据数据的特点进行作业执行过程中的动态调整。
* 在资源保障方面,为应对挑战#4,Fuxi 对高优先级作业 (主要是高优先级作业)采取了更严格、更细粒度的资源保障措施,如资源调度的**交互式抢占功能**,和作业优先级保障管控等。目前线上最高优先级的作业基本能在**90s内抢占到资源。**
* 其他如业务调优支持等:如业务数据压测配合,与作业调优等。
StreamlineX + Shuffle Service
=============================
**挑战**
上面提到今年双十一数据量翻倍接近EB级,作业量接近千万,整体资源使用也比较紧张,通过以往经验分析,双十一影响最关键的模块就是Streamline (在其他数据处理引擎也被称为Shuffle或Exchange),各种极端场景层出不穷,并发度超过5万以上的Task,多达几亿条的热点Key,单Worker数据膨胀上千倍等全方位覆盖的超压力数据场景,都将极大影响Streamline模块的稳定运行,从而对集群磁盘IO的稳定性,数据文件读写性能,机器资源竞抢性能,长尾Worker PVC(Pipe Version Control,提供了某些特定情况下作业失败重跑的机制)重跑等各方面产生影响,任何一个状况没有得到及时的自动化解决,都有可能导致基线作业破线引发故障。
**Streamline 与 Shuffle Service 概述**
* **Streamline**
在其他OLAP或MPP系统中,也有类似组件被称为Shuffle或Exchange,在MaxCompute SQL中该组件涉及的功能更加完善,性能更优,主要包含但不限于分布式运行的Task之间数据序列化,压缩,读写传输,分组合并,排序等操作。SQL中一些耗时算子的分布式实现基本都需要用到这个模块,比如join,groupby,window等等,因此它绝对是CPU,memory,IO等资源的消耗大户,在大部分作业中运行时间占比整个sql运行时间30%以上,一些大规模作业甚至可以达到60%以上,这对于MaxCompute SQL日均近千万任务量,日均处理数据接近EB级的服务来说,性能每提升1个多百分点,节省的机器资源都是以上千台计,因此对该组件的持续重构优化一直是MaxCompute SQL团队性能提升指标的重中之重。今年双十一应用的SLX就是完全重写的高性能Streamline架构。
* **Shuffle Service **
在MaxCompute SQL中,它主要用于管理全集群所有作业Streamline数据的底层传输方式和物理分布。调度到不同机器上成千上万的Worker需要通过精准的数据传递,才能协作完成整体的任务。在服务MaxCompute这样的数据大户时,能否高效、稳定地完成每天10万台机器上千万量级worker间传输几百PB数据量的数据shuffle工作,很大意义上决定了集群整体的性能和资源利用效率。 Shuffle Service放弃了以磁盘文件为基础的主流shuffle文件存储方式,突破了机械硬盘上文件随机读的性能和稳定性短板;基于shuffle数据动态调度的思想,令shuffle流程成为了作业运行时实时优化的数据流向、排布和读取的动态决策。对准实时作业,通过解构DAG上下游调度相比network shuffle性能相当,资源消耗降低50%+。
**StreamlineX + Shuffle Service关键技术**
* **StreamlineX (SLX) 架构与优化设计**
SLX逻辑功能架构如图所示,主要包含了SQL runtime层面的数据处理逻辑重构优化,包括优化数据处理模式,算法性能
提升,内存分配管理优化,挖掘硬件性能等各方面来提升计算性能,而且底座结合了全新设计的负责数据传输的Fuxi ShuffleService服务来优化IO读写以及Worker容错性等方面,让SLX在各种数据模式以及数据规模下都能够有很好的性能提升和高效稳定的运行。
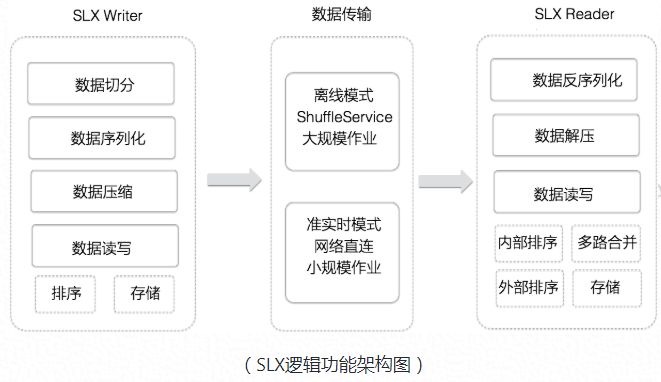
SQL Runtime SLX主要包含Writer和Reader两部分,下面简要介绍其中部分优化设计:
1. 框架结构合理划分: Runtime Streamline 和fuxi sdk 解耦,Runtime 负责数据处理逻辑,Fuxi SDK 负责底层数据流传输。代码可维护性,功能可扩张性,性能调优空间都显著增强。
2. 支持 GraySort 模式: Streamline Writer 端只分组不排序,逻辑简单,省去数据内存拷贝开销以及相关耗时操作,Reader 端对全量数据排序。整体数据处理流程 Pipeline 更加高效,性能显著提升。
3. 支持 Adaptive 模式: StreamlineReader支持不排序和排序模式切换,来支持一些 AdaptiveOperator 的需求,并且不会产生额外的 IO 开销,回退代价小,Adaptive 场景优化效果显著。
4. CPU 计算效率优化: 对耗时计算模块重新设计 CPU 缓存优化的数据结构和算法,通过减少 cache miss,减少函数调用开销,减少 cpu cache thrashing,提升 cache 的有效利用率等手段,来提升运算效率。
5. IO 优化:支持多种压缩算法和 Adaptive 压缩方式,并重新设计 Shuffle 传输数据的存储格式,有效减少传输的 IO 量。
6. 内存优化: 对于 Streamline Writer 和 Reader 内存分配更加合理,会根据实际数据量来按需分配内存,尽可能减少可能产生的 Dump 操作。
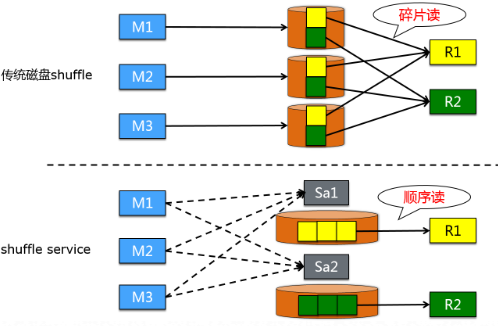
根据以往双十一的经验,11月12日凌晨基线任务数据量大幅增加,shuffle过程会受到巨大的挑战,这通常也是造成当天基线延迟的主要原因,下面列出了传统磁盘shuffle的主要问题:
* 碎片读:一个典型的2k\*1k shuffle pipe在上游每个mapper处理256MB数据时,一个mapper写给一个reducer的数据量平均为256KB,而从HDD磁盘上一次读小于256KB这个级别的数据量是很不经济的,高iops低throughput严重影响作业性能。
* 稳定性:由于HDD上严重的碎片读现象,造成reduce input阶段较高的出错比率,触发上游重跑生成shuffle数据更是让作业的执行时间成倍拉长。
Shuffle Service彻底解决了以上问题。经过此次双11的考验,结果显示线上集群的压力瓶颈已经从之前的磁盘,转移到CPU资源上。双十一当天基线作业执行顺畅,集群整体运行持续保持稳定。
Shuffle Service 主要功能有:
* **agent merge**:彻底解决传统磁盘shuffle模式中的碎片读问题;
* **灵活的异常处理机制**:相较于传统磁盘shuffle模式,在应对坏境异常时更加稳定高效;
* **数据动态调度**:运行时为任务选择最合适的shuffle数据来源
* **内存&PreLaunch对准实时的支持**:性能与network shuffle相当的情况下,资源消耗更少
**StreamlineX + Shuffle Service双十一线上成果**
为了应对上面挑战,突破现有资源瓶颈,一年多前MaxCompute SQL就启动性能持续极限优化项目,其中最关键之一就是StreamlineX (SLX)项目,它完全重构了现有的Streamline框架,从合理设计高扩展性架构,数据处理模式智能化匹配,内存动态分配和性能优化,Adaptive算法匹配,CPU Cache访问友好结构设计,基于 Fuxi Shuffle Service 服务优化数据读写IO和传输等各方面进行重构优化升级后的高性能框架。至双十一前,日均95%以上弹内SQL作业全部采用SLX,90%以上的Shuffle流量来自SLX,0故障,0回退的完成了用户透明无感知的热升级,在保证平稳上线的基础上,SLX在性能和稳定性上超预期提升效果在双十一当天得到充分体现,基于线上全量高优先级基线作业进行统计分析:
* 在性能方面,全量准实时SQL作业e2e运行速度提升15%+,全量离线作业的Streamline模块Throughput(GB/h)提升100%
* 在IO读写稳定性方面,基于FuxiShuffleService服务,整体集群规模平均有效IO读写Size提升100%+,磁盘压力下降20%+;
* 在作业长尾和容错上,作业Worker发生PVC的概率下降到仅之前的几十分之一;
* 在资源优先级抢占方面,ShuffleService保障高优先级作业shuffle 数据传输比低优先级作业降低25%+;
正是这些超预期优化效果,MaxCompaute 双十一当天近千万作业,涉及到近10万台服务器节省了近20%左右的算力,而且针对各种极端场景也能智能化匹配最优处理模式,做到完全掌控未来数据量不断增长的超大规模作业的稳定产出。上面性能数据统计是基于全量高优先级作业的一个平均结果,实际上SLX在很多大规模数据场景下效果更加显著,比如在线下tpch和tpcds 10TB测试集资源非常紧张的场景下,SQL e2e运行速度提升近一倍,Shuffle模块提升达2倍。
**StreamlineX+Shuffle Service 展望**
高性能SLX框架经过今年双十一大考觉不是一个结束,而是一个开始,后续我们还会不断的完善功能,打磨性能。比如持续引入高效的排序,编码,压缩等算法来Adaptive匹配各种数据Parttern,根据不同数据规模结合ShuffleService智能选择高效数据读写和传输模式,RangePartition优化,内存精准控制,热点模块深度挖掘硬件性能等各方向持续发力,不断节省公司成本,技术上保持大幅领先业界产品。
DAG 2.0
=======
**挑战**
双十一大促场景下,除了数据洪峰和超过日常作业的规模,数据的分布与特点也与平常大不相同。这种特殊的场景对分布式作业的调度执行框架提出了多重挑战,包括:
* 处理双十一规模的数据,单个作业规模超过数十万计算节点,并有超过百亿的物理边连接。在这种规模的作业上要保证调度的敏捷性,需要实现全调度链路overhead的降低以及无阻塞的调度。
* 在基线时段集群异常繁忙,各个机器的网络/磁盘/CPU/内存等等各个方面均会收到比往常更大的压力,从而造成的大量的计算节点异常。而分布式调度计算框架在这个时候,不仅需要能够及时监测到逻辑计算节点的异常进行最有效的重试,还需要能够智能化的及时判断/隔离/预测可能出现问题的物理机器,确保作业在大的集群压力下依然能够正确完成。
* 面对与平常特点不同的数据,许多平时的执行计划在双十一场景上可能都不再适用。这个时候调度执行框架需要有足够的智能性,来选择合理的物理执行计划;以及足够的动态性,来根据实时数据特点对作业的方方面面做出及时的必要调整。这样才能避免大量的人工干预和临时人肉运维。
今年双十一,适逢计算平台的核心调度执行框架全新架构升级- DAG 2.0正在全面推进上线,DAG 2.0 很好的解决了上述几个挑战。
**DAG 2.0 概述**
现代分布式系统作业执行流程,通常通过一个有向无环图(DAG)来描述。DAG调度引擎,是分布式系统中唯一需要和几乎所有上下游(资源管理,机器管理,计算引擎, shuffle组件等等)交互的组件,在分布式系统中起了重要的协调管理,承上启下作用。作为计算平台各种上层计算引擎(MaxCompute, PAI等)的底座,伏羲的DAG组件在过去十年支撑了上层业务每天数百万的分布式作业运行,以及数百PB的数据处理。而在计算引擎本身能力不断增强,作业种类多样化的背景下,对DAG架构的动态性,灵活性,稳定性等多个方面都提出了更高的需求。在这个背景下,伏羲团队启动了DAG 2.0架构升级。引入了一个,在代码和功能层面,均是全新的DAG引擎,来更好的支持计算平台下个十年的发展。
这一全新的架构,赋予了DAG更敏捷的调度执行能力,并在分布式作业执行的动态性,灵活性等方面带来了质的提升,在与上层计算引擎紧密结合后,能提供更准确的动态执行计划调整能力,从而为支持各种大规模作业提供了更好的保障。例如在最简单的MR作业测试中,DAG 2.0调度系统本身的敏捷度和整个处理流程中的全面去阻塞能力, 能为大规模的MR作业(10万并发)带来将近50%的性能提升。而在更接近线上SQL workload特点的中型(1TB TPCDS)作业中,调度能力的提升能带来20%+的e2e时间缩短。
DAG 2.0的架构设计中结合了过去10年支持集团内外各种计算任务的经验,系统的对实时机器管理框架,backup instance策略以及容错机制等方面进行了考虑和设计,为支持线上多种多样的实际集群环境打下了重要基础。而另一挑战是,2.0架构要在日常数百万分布式作业的体量上做到完全的上线,在飞行中换引擎。从FY20财年初开始,DAG2.0推进线上升级,至今已经实现了在MaxCompute离线作业,PAI平台Tensorflow CPU/GPU作业等每天数百万作业的完全覆盖。并经过项目组所有成员的共同努力,在双十一当天交出了一份满意的答卷。
**DAG 2.0 关键技术**
能取得上述线上结果,和DAG2.0众多的技术创新密不可分,受篇幅限制,这里主要选取和双11运行稳定性相关的两个方面做重点介绍。
* **完善的错误处理能力**
在分布式环境中由于机器数量巨大,单机发生故障的概率非常高,因此容错能力是调度系统的一个重要能力。为了更好的管理机器状态,提前发现故障机器并进行主动归并,DAG2通过完整的机器状态管理,完善了机器错误的处理能力:
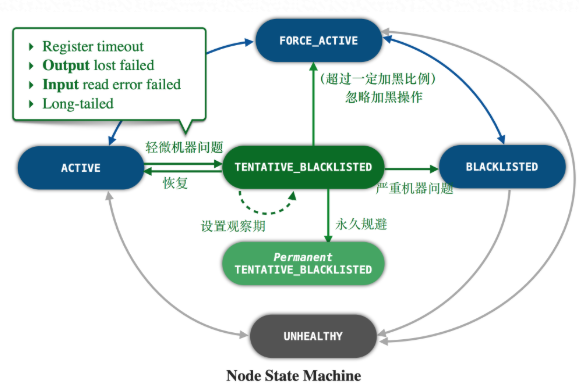
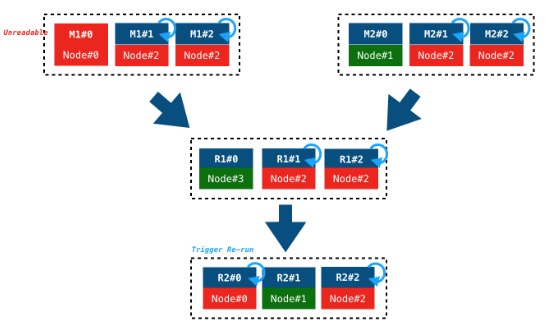
如上图所示,DAG2将机器分为多个状态。并根据一系列不同的指标来触发在不同状态之间的转换。对于不同状态的机器,根据其健康程度,进行主动规避,计算任务迁移,以及计算任务主动重跑等操作。将机器问题造成的作业运行时间拉长,甚至作业失败的可能性降到最低。
另一方面,在一个DAG上,当下游读取数据失败时,需要触发上游的重跑,而在发生严重机器问题时,多个任务的链式重跑,会造成作业的长时间延迟,对于基线作业的及时产出造成严重影响。DAG2.0上实现了一套基于血缘回溯的主动容错策略(如下图),这样的智能血缘回溯,能够避免了层层试探,层层重跑,在集群压力较大时,能够有效的节约运行时间,避免资源浪费。
* **灵活的动态逻辑图执行策略--Conditional join**
分布式SQL中,map join是一个比较常见的优化,其实现原理对小表避免shuffle,而是直接将其全量数据broadcast到每个处理大表的分布式计算节点上,通过在内存中直接建立hash表,完成join操作。map join优化能大量减少额外shuffle和排序开销并避免shuffle过程中可能出现的数据倾斜,提升作业运行性能。但是其局限性也同样显著:如果小表无法fit进单机内存,那么在试图建立内存中的hash表时就会因为OOM而导致整个分布式作业的失败。所以虽然map join在正确使用时,可以带来较大的性能提升,但实际上优化器在产生map join的plan时需要偏保守,导致错失了很多优化机会。而即便是如此,依然没有办法完全避免map join OOM的问题。
基于DAG 2.0的动态逻辑图执行能力,MaxCompute支持了开发的conditional join功能:在对于join使用的算法无法被事先确定时,允许优化器提供一个conditional DAG,这样的DAG同时包括使用两种不同join的方式对应的不同执行计划支路。在实际执行时,AM根据上游产出数据量,动态选择一条支路执行(plan A or plan B)。这样子的动态逻辑图执行流程,能够保证每次作业运行时都能根据实际作业数据特性,选择最优的执行计划,详见下图:
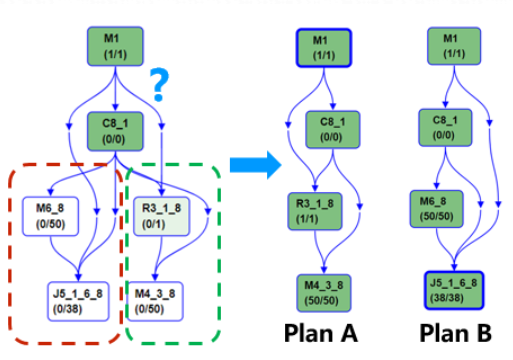
出于对上线节奏把控的考虑,双十一期间conditional join尚未覆盖高优先级作业。双十一期间,我们也看到了重要基线上由于数据膨胀导致Mapjoin hint失效,作业OOM需要临时调参;以及因为Mapjoin未能被正确选中,而导致作业未能选中优化执行计划而延迟完成的情况。在conditional join在重要基线上线后,能够有效的避免这一情况,让基线的产出更加流畅。
**DAG 2.0 双十一线上成果**
双十一作为阿里集团所有技术线的大考,对于DAG2.0这一全新的组件,同样是一个重要的考验,也是DAG2线上升级的一个重要的里程碑:
* 双11当天,DAG2.0覆盖支持线上80%+project。截至目前已完成全面上线,日均支持几百万的离线作业执行。对于signature相同的基线作业,DAG 2.0下instance 运行的overhead开销有1到2倍的降低。
* 双11当天,使用DAG 2.0的高优先级基线在双十一数据洪峰下,没有任何人工干预的前提下,未发生任何作业失败重跑。其中,DAG2.0提供的实时机器管理,backup instance策略等智能容错机制发挥了重要作用。
* 支持开发环境中近百万量级作业,在作业平均规模更大的前提下,双11期间毫秒级(执行时间小于1s的作业)分布作业占比相比1.0提升20%+。新框架上更高效的资源流转率也带来了资源利用率的明显提升:等待在线资源超时而回退的在线作业比例降低了将近50%。
* DAG 2.0还支持了PAI引擎,为双十一期间的搜索、推荐等业务的模型提前训练提供了有力的支持。双十一前PAI平台的所有TensorFlow CPU/GPU作业,就已经全量迁移到DAG 2.0上,其更有效的容错和资源使用的提升,保证了各条业务线上模型的及时产出。
除了基础提升调度能力提升带来的性能红利外,DAG2在动态图亮点功能上也完成了新的突破。包括增强Dynamic Parrellism, LIMIT优化, Conditional Join等动态图功能完成上线或者正在上线推动中。其中Conditional Join一方面保证了优化的执行计划能尽可能的被选用,同时也保证了不会因为错误选择而带来OOM导致作业失败,通过运行时数据统计来动态决定是否使用Mapjoin,保证更加准确决策。双十一前在集团内部做了灰度上线,线上日均生效的conditionl节点**10万+**,其中应用Map join的节点占比超过了**90%**,**0 OOM发生**。推广的过程中我们也收到了各个BU多个用户的真实反馈,使用conditional join后,因为能选择最优的执行计划,多个场景上作业的运行时间,**都从几个小时降低到了30分钟以下**。
**DAG 2.0 展望**
在双十一值班的过程中,我们依然看到了大促场景下因为不同的数据分布特点,数据的倾斜/膨胀对于分布式作业整体的完成时间影响非常大。而这些问题在DAG 2.0完备的动态图调度和运行能力上,都能得到较好的解决,相关功能正在排期上线中。
一个典型的例子是dynamic partition insert的场景,在某个高优先级作业的场景上,一张重要的业务表直接采用动态分区的方式导入数据导致表文件数过多,后续基线频繁访问该表读取数据导致pangu master持续被打爆,集群处于不可用状态。采用DAG2.0的Adaptive Shuffle功能之后,线下验证作业运行时间**由30+小时降低到小于30分钟**,而产生的文件数相比于关闭reshuffle的方式**降低了一个数量级**,在保障业务数据及时产出的前提下,能极大缓解pangu master的压力。动态分区场景在弹内生产和公共云生产都有广阔的应用场景,随着Adaptive Shuffle的上线,dynamic insert将是第一个解决的比较彻底的数据倾斜场景。此外,DAG2.0也持续探索其他数据倾斜(data skew)的处理,例如join skew等,相信随着在2.0上更多优化功能的开发,我们的执行引擎能做到更动态,更智能化,包括数据倾斜问题在内的一众线上痛点问题,将可以得到更好的解决。今天最好的表现,是明天最低的要求。我们相信明年的双十一,在面对更大的数据处理量时,计算平台的双十一保障能够更加的自动化,通过分布式作业运行中的动态化调整,在更少人工干预的前提下完成。
资源调度的交互式抢占
==========
**挑战**
FuxiMaster是fuxi的资源调度器,负责将计算资源分配给不同的计算任务。针对MaxComput超大规模计算场景下,不同应用间多样的资源需求,过去几年资源调度团队对的核心调度逻辑做了极致的性能优化,调度延时控制在了10微秒级别,集群资源的高效流转为MaxComputer历年双十一大促的稳定运行提供了强有力的保障。
而其中高先级基线作业的按时完成是双十一大促成功的重要标志,也是资源保障中的重中之重。除了空闲资源的优先分配,还需要对低优先级作业占用的资源进行腾挪,在不影响集群整体利用率的前提下,快速地将资源分配给高优先级基线作业。
**交互式抢占概述**
在高负载的集群,若高优先级作业无法及时拿到资源,传统的做法是通过抢占,直接杀掉低优先级作业,然后将资源分配给高优先级作业,这种“暴力”抢占有资源快速腾挪的特点,但抢占“杀人”也会导致用户作业中途被杀,计算资源浪费的缺点。交互式抢占是指在明确资源从低优先级流向高优先级的前提下,不立即杀掉低优先级作业,而是通过协议,让低优先级作业尽快在可接受的时间内(目前是90s)快速跑完,既不浪费集群的计算资源,同时也保障了高优先级作业的资源供给。
目前弹内线上针对高优先级SU(schedule unit,是资源管理的基本单位)开启组内交互式抢占,在大多情况下可以保障基线作业的资源供给。然而,目前即使通过交互式抢占也还会存在一些作业无法及时获得资源的情况。例如,高优先级交互式抢占每隔30s的触发处理高优先的SU数量受全局配置约束,而该段时间还存在大量其他早已经提交进来的高优先级SU,会导致该作业的SU被轮空。另外,交互式抢占指令发出后,需要对应instance结束后定向还这份资源,而对应的instance的运行时间都非常长,导致交互式无法及时拿回对应的资源。 基于上述问题,我们进一步优化了交互式抢占策略。
**交互式抢占关键技术**
针对前文提到的几个问题,交互式抢占做了如下优化:
* 通过性能优化,放宽了高优先级每轮处理的SU限制个数
* 交互式抢占超时后强制回收预留的低优先级资源,对于优先启动的、占据大量资源、instance运行时间较长的低优先级作业,需要强制回收资源。
* 采用预留外的资源供给高优先级资源,可以通过预留外的其他资源为交互式抢占的SU继续分配资源,同时抵消对应的交互式抢占部分。
**双十一线上成果**
2019双十一期间,面对远超以往的数据量,所有的高优先级作业顺利按期产出,资源调度方面顺利保障了基线资源供给,其丝般顺滑程度让整个基线保障的过程几乎感受不到资源调度的存在。其中基线作业交互式抢占以及加速功能提供了有效的资源保障能力,及时、有效的抢占到所需资源。下文给出了某个云上集群的资源供给情况。
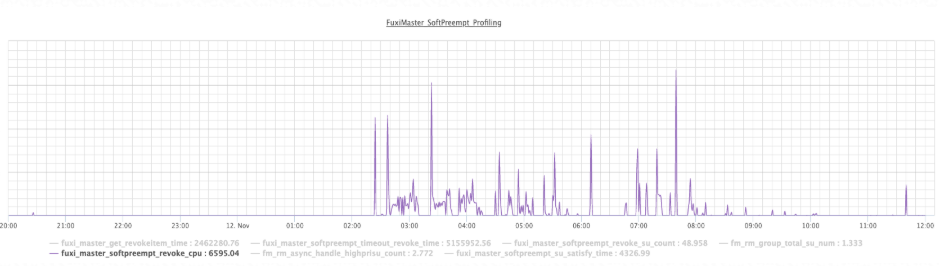
* **交互式抢占加速为基线作业快速提供可用资源**
从下面几张图中可以看到,在基线时间段(00:00 ~ 09:00), 基线作业超时拿不到资源发起交互式抢占revoke的频率明显高于其他时段, 这意味着通过交互式抢占加速的手段基线作业可以顺利拿到所需资源。双十一期间的线上运行情况,也证明了 在资源压力大的情况下,高优先级基线作业明显通过了交互式抢占revoke获得了资源。
* **基线作业的SU拿资源时间比例分布**
下边为主要几个集群SU拿资源的时间分布 (fuxi基本调度单元), 可以发现这几个集群90%分位拿资源的时间基本都在1分钟左右(**符合线上基线作业等待资源达到90s进行抢占配置预期**)。

[原文链接](https://link.zhihu.com/?target=https%3A//yq.aliyun.com/articles/739645%3Futm_content%3Dg_1000094672)
本文为阿里云内容,未经允许不得转载。
随着阿里经济体和阿里云业务需求(尤其是双十一)的不断丰富,伏羲的内涵也不断扩大,从单一的资源调度器(对标开源系统的YARN)扩展成大数据的核心调度服务,覆盖数据调度(Data Placement)、资源调度(Resouce Management)、计算调度(Application Manager)、和本地微(自治)调度等多个领域,并在每一个细分领域致力于打造超越业界主流的差异化能力。
过去十年来,伏羲在技术能力上每年都有新的进展和突破,2013年5K,2015年Sortbenchmark世界冠军,2017年超大规模离在/在离线混部能力,2019年的 Yugong 发布并且论文被VLDB2019接受等。随着 Fuxi 2.0 首次亮相2019双11,今年飞天大数据平台在混部侧支持和基线保障2个方面均顺利完成了目标。其中,混部支持了双十一 60%在线交易洪峰的流量,超大规模混部调度符合预期。在基线保障方面,单日数据处理 970PB,较去年增长超过60%。在千万级别的作业上,不需要用户额外调优,基本做到了无人工干预的系统自动化。
新的挑战
====
随着业务和数据的持续高速增长,MaxCompute 双十一的作业量和计算数据量每年的增速都保持在60%以上 。
2019双十一,MaxCompute 日计算数据量规模已接近EB级,作业量也到了千万量级,在如此大规模和资源紧张的情况下,要确保双十一稳定运行,所有重要基线作业按时产出压力相当之大。

**在双十一独特的大促场景下,2019双11的挑战主要来自以下几个方面:**
1. 超大规模计算场景下,以及资源紧张的情况下,如何进一步提升平台的整体性能,来应对业务的持续高速增长。
2. 双十一会给MaxCompute带来全方面超压力的极端场景,如几亿条的热点key、上千倍的数据膨胀等,这对集群磁盘IO的稳定性、数据文件读写性能、长尾作业重跑等各方面都是挑战。
3. 近千万量级作业的规模下,如何做到敏捷、可靠、高效的分布式作业调度执行。
4. 以及对高优先级作业(如重要业务基线)的资源保障手段。
5. 今年也是云上集群首次参与双十一,并且开始支持混部。
如何应对挑战
======
为了应对上述挑战,与往年相比,除了常规的HBO等调整之外,飞天大数据平台加速了过去1-2年中技术积累成果的上线,尤其是 **Fuxi 2.0 首次亮相双十一**,最终在单日任务量近千万、单日计算量近千PB的压力下,保障了基线全部按时产出。
* 在平台性能优化方面,对于挑战#1和#2,**StreamlineX + Shuffle Service** 根据实时数据特征自动智能化匹配高效的处理模式和算法,挖掘硬件特性深度优化IO,内存,CPU等处理效率,在减少资源使用的同时,**让全量SQL平均处理速度提升将近20%**,出错重试率下降至原来的几十分之一,大大提了升MaxCompute 平台整体效能。
* 在分布式作业调度执行方面,对于挑战#3,**DAG 2.0 **提供了更敏捷的调度执行能力,和全面去阻塞能力,能为大规模的MR作业带来**近50%的性能提升**。同时DAG动态框架的升级,也为分布式作业的调度执行带来了更灵活的动态能力,能根据数据的特点进行作业执行过程中的动态调整。
* 在资源保障方面,为应对挑战#4,Fuxi 对高优先级作业 (主要是高优先级作业)采取了更严格、更细粒度的资源保障措施,如资源调度的**交互式抢占功能**,和作业优先级保障管控等。目前线上最高优先级的作业基本能在**90s内抢占到资源。**
* 其他如业务调优支持等:如业务数据压测配合,与作业调优等。
StreamlineX + Shuffle Service
=============================
**挑战**
上面提到今年双十一数据量翻倍接近EB级,作业量接近千万,整体资源使用也比较紧张,通过以往经验分析,双十一影响最关键的模块就是Streamline (在其他数据处理引擎也被称为Shuffle或Exchange),各种极端场景层出不穷,并发度超过5万以上的Task,多达几亿条的热点Key,单Worker数据膨胀上千倍等全方位覆盖的超压力数据场景,都将极大影响Streamline模块的稳定运行,从而对集群磁盘IO的稳定性,数据文件读写性能,机器资源竞抢性能,长尾Worker PVC(Pipe Version Control,提供了某些特定情况下作业失败重跑的机制)重跑等各方面产生影响,任何一个状况没有得到及时的自动化解决,都有可能导致基线作业破线引发故障。
**Streamline 与 Shuffle Service 概述**
* **Streamline**
在其他OLAP或MPP系统中,也有类似组件被称为Shuffle或Exchange,在MaxCompute SQL中该组件涉及的功能更加完善,性能更优,主要包含但不限于分布式运行的Task之间数据序列化,压缩,读写传输,分组合并,排序等操作。SQL中一些耗时算子的分布式实现基本都需要用到这个模块,比如join,groupby,window等等,因此它绝对是CPU,memory,IO等资源的消耗大户,在大部分作业中运行时间占比整个sql运行时间30%以上,一些大规模作业甚至可以达到60%以上,这对于MaxCompute SQL日均近千万任务量,日均处理数据接近EB级的服务来说,性能每提升1个多百分点,节省的机器资源都是以上千台计,因此对该组件的持续重构优化一直是MaxCompute SQL团队性能提升指标的重中之重。今年双十一应用的SLX就是完全重写的高性能Streamline架构。
* **Shuffle Service **
在MaxCompute SQL中,它主要用于管理全集群所有作业Streamline数据的底层传输方式和物理分布。调度到不同机器上成千上万的Worker需要通过精准的数据传递,才能协作完成整体的任务。在服务MaxCompute这样的数据大户时,能否高效、稳定地完成每天10万台机器上千万量级worker间传输几百PB数据量的数据shuffle工作,很大意义上决定了集群整体的性能和资源利用效率。 Shuffle Service放弃了以磁盘文件为基础的主流shuffle文件存储方式,突破了机械硬盘上文件随机读的性能和稳定性短板;基于shuffle数据动态调度的思想,令shuffle流程成为了作业运行时实时优化的数据流向、排布和读取的动态决策。对准实时作业,通过解构DAG上下游调度相比network shuffle性能相当,资源消耗降低50%+。
**StreamlineX + Shuffle Service关键技术**
* **StreamlineX (SLX) 架构与优化设计**
SLX逻辑功能架构如图所示,主要包含了SQL runtime层面的数据处理逻辑重构优化,包括优化数据处理模式,算法性能
提升,内存分配管理优化,挖掘硬件性能等各方面来提升计算性能,而且底座结合了全新设计的负责数据传输的Fuxi ShuffleService服务来优化IO读写以及Worker容错性等方面,让SLX在各种数据模式以及数据规模下都能够有很好的性能提升和高效稳定的运行。

SQL Runtime SLX主要包含Writer和Reader两部分,下面简要介绍其中部分优化设计:
1. 框架结构合理划分: Runtime Streamline 和fuxi sdk 解耦,Runtime 负责数据处理逻辑,Fuxi SDK 负责底层数据流传输。代码可维护性,功能可扩张性,性能调优空间都显著增强。
2. 支持 GraySort 模式: Streamline Writer 端只分组不排序,逻辑简单,省去数据内存拷贝开销以及相关耗时操作,Reader 端对全量数据排序。整体数据处理流程 Pipeline 更加高效,性能显著提升。
3. 支持 Adaptive 模式: StreamlineReader支持不排序和排序模式切换,来支持一些 AdaptiveOperator 的需求,并且不会产生额外的 IO 开销,回退代价小,Adaptive 场景优化效果显著。
4. CPU 计算效率优化: 对耗时计算模块重新设计 CPU 缓存优化的数据结构和算法,通过减少 cache miss,减少函数调用开销,减少 cpu cache thrashing,提升 cache 的有效利用率等手段,来提升运算效率。
5. IO 优化:支持多种压缩算法和 Adaptive 压缩方式,并重新设计 Shuffle 传输数据的存储格式,有效减少传输的 IO 量。
6. 内存优化: 对于 Streamline Writer 和 Reader 内存分配更加合理,会根据实际数据量来按需分配内存,尽可能减少可能产生的 Dump 操作。
根据以往双十一的经验,11月12日凌晨基线任务数据量大幅增加,shuffle过程会受到巨大的挑战,这通常也是造成当天基线延迟的主要原因,下面列出了传统磁盘shuffle的主要问题:
* 碎片读:一个典型的2k\*1k shuffle pipe在上游每个mapper处理256MB数据时,一个mapper写给一个reducer的数据量平均为256KB,而从HDD磁盘上一次读小于256KB这个级别的数据量是很不经济的,高iops低throughput严重影响作业性能。
* 稳定性:由于HDD上严重的碎片读现象,造成reduce input阶段较高的出错比率,触发上游重跑生成shuffle数据更是让作业的执行时间成倍拉长。
Shuffle Service彻底解决了以上问题。经过此次双11的考验,结果显示线上集群的压力瓶颈已经从之前的磁盘,转移到CPU资源上。双十一当天基线作业执行顺畅,集群整体运行持续保持稳定。

Shuffle Service 主要功能有:
* **agent merge**:彻底解决传统磁盘shuffle模式中的碎片读问题;
* **灵活的异常处理机制**:相较于传统磁盘shuffle模式,在应对坏境异常时更加稳定高效;
* **数据动态调度**:运行时为任务选择最合适的shuffle数据来源
* **内存&PreLaunch对准实时的支持**:性能与network shuffle相当的情况下,资源消耗更少
**StreamlineX + Shuffle Service双十一线上成果**
为了应对上面挑战,突破现有资源瓶颈,一年多前MaxCompute SQL就启动性能持续极限优化项目,其中最关键之一就是StreamlineX (SLX)项目,它完全重构了现有的Streamline框架,从合理设计高扩展性架构,数据处理模式智能化匹配,内存动态分配和性能优化,Adaptive算法匹配,CPU Cache访问友好结构设计,基于 Fuxi Shuffle Service 服务优化数据读写IO和传输等各方面进行重构优化升级后的高性能框架。至双十一前,日均95%以上弹内SQL作业全部采用SLX,90%以上的Shuffle流量来自SLX,0故障,0回退的完成了用户透明无感知的热升级,在保证平稳上线的基础上,SLX在性能和稳定性上超预期提升效果在双十一当天得到充分体现,基于线上全量高优先级基线作业进行统计分析:
* 在性能方面,全量准实时SQL作业e2e运行速度提升15%+,全量离线作业的Streamline模块Throughput(GB/h)提升100%
* 在IO读写稳定性方面,基于FuxiShuffleService服务,整体集群规模平均有效IO读写Size提升100%+,磁盘压力下降20%+;
* 在作业长尾和容错上,作业Worker发生PVC的概率下降到仅之前的几十分之一;
* 在资源优先级抢占方面,ShuffleService保障高优先级作业shuffle 数据传输比低优先级作业降低25%+;
正是这些超预期优化效果,MaxCompaute 双十一当天近千万作业,涉及到近10万台服务器节省了近20%左右的算力,而且针对各种极端场景也能智能化匹配最优处理模式,做到完全掌控未来数据量不断增长的超大规模作业的稳定产出。上面性能数据统计是基于全量高优先级作业的一个平均结果,实际上SLX在很多大规模数据场景下效果更加显著,比如在线下tpch和tpcds 10TB测试集资源非常紧张的场景下,SQL e2e运行速度提升近一倍,Shuffle模块提升达2倍。
**StreamlineX+Shuffle Service 展望**
高性能SLX框架经过今年双十一大考觉不是一个结束,而是一个开始,后续我们还会不断的完善功能,打磨性能。比如持续引入高效的排序,编码,压缩等算法来Adaptive匹配各种数据Parttern,根据不同数据规模结合ShuffleService智能选择高效数据读写和传输模式,RangePartition优化,内存精准控制,热点模块深度挖掘硬件性能等各方向持续发力,不断节省公司成本,技术上保持大幅领先业界产品。
DAG 2.0
=======
**挑战**
双十一大促场景下,除了数据洪峰和超过日常作业的规模,数据的分布与特点也与平常大不相同。这种特殊的场景对分布式作业的调度执行框架提出了多重挑战,包括:
* 处理双十一规模的数据,单个作业规模超过数十万计算节点,并有超过百亿的物理边连接。在这种规模的作业上要保证调度的敏捷性,需要实现全调度链路overhead的降低以及无阻塞的调度。
* 在基线时段集群异常繁忙,各个机器的网络/磁盘/CPU/内存等等各个方面均会收到比往常更大的压力,从而造成的大量的计算节点异常。而分布式调度计算框架在这个时候,不仅需要能够及时监测到逻辑计算节点的异常进行最有效的重试,还需要能够智能化的及时判断/隔离/预测可能出现问题的物理机器,确保作业在大的集群压力下依然能够正确完成。
* 面对与平常特点不同的数据,许多平时的执行计划在双十一场景上可能都不再适用。这个时候调度执行框架需要有足够的智能性,来选择合理的物理执行计划;以及足够的动态性,来根据实时数据特点对作业的方方面面做出及时的必要调整。这样才能避免大量的人工干预和临时人肉运维。
今年双十一,适逢计算平台的核心调度执行框架全新架构升级- DAG 2.0正在全面推进上线,DAG 2.0 很好的解决了上述几个挑战。
**DAG 2.0 概述**
现代分布式系统作业执行流程,通常通过一个有向无环图(DAG)来描述。DAG调度引擎,是分布式系统中唯一需要和几乎所有上下游(资源管理,机器管理,计算引擎, shuffle组件等等)交互的组件,在分布式系统中起了重要的协调管理,承上启下作用。作为计算平台各种上层计算引擎(MaxCompute, PAI等)的底座,伏羲的DAG组件在过去十年支撑了上层业务每天数百万的分布式作业运行,以及数百PB的数据处理。而在计算引擎本身能力不断增强,作业种类多样化的背景下,对DAG架构的动态性,灵活性,稳定性等多个方面都提出了更高的需求。在这个背景下,伏羲团队启动了DAG 2.0架构升级。引入了一个,在代码和功能层面,均是全新的DAG引擎,来更好的支持计算平台下个十年的发展。
这一全新的架构,赋予了DAG更敏捷的调度执行能力,并在分布式作业执行的动态性,灵活性等方面带来了质的提升,在与上层计算引擎紧密结合后,能提供更准确的动态执行计划调整能力,从而为支持各种大规模作业提供了更好的保障。例如在最简单的MR作业测试中,DAG 2.0调度系统本身的敏捷度和整个处理流程中的全面去阻塞能力, 能为大规模的MR作业(10万并发)带来将近50%的性能提升。而在更接近线上SQL workload特点的中型(1TB TPCDS)作业中,调度能力的提升能带来20%+的e2e时间缩短。
DAG 2.0的架构设计中结合了过去10年支持集团内外各种计算任务的经验,系统的对实时机器管理框架,backup instance策略以及容错机制等方面进行了考虑和设计,为支持线上多种多样的实际集群环境打下了重要基础。而另一挑战是,2.0架构要在日常数百万分布式作业的体量上做到完全的上线,在飞行中换引擎。从FY20财年初开始,DAG2.0推进线上升级,至今已经实现了在MaxCompute离线作业,PAI平台Tensorflow CPU/GPU作业等每天数百万作业的完全覆盖。并经过项目组所有成员的共同努力,在双十一当天交出了一份满意的答卷。
**DAG 2.0 关键技术**
能取得上述线上结果,和DAG2.0众多的技术创新密不可分,受篇幅限制,这里主要选取和双11运行稳定性相关的两个方面做重点介绍。
* **完善的错误处理能力**
在分布式环境中由于机器数量巨大,单机发生故障的概率非常高,因此容错能力是调度系统的一个重要能力。为了更好的管理机器状态,提前发现故障机器并进行主动归并,DAG2通过完整的机器状态管理,完善了机器错误的处理能力:

如上图所示,DAG2将机器分为多个状态。并根据一系列不同的指标来触发在不同状态之间的转换。对于不同状态的机器,根据其健康程度,进行主动规避,计算任务迁移,以及计算任务主动重跑等操作。将机器问题造成的作业运行时间拉长,甚至作业失败的可能性降到最低。
另一方面,在一个DAG上,当下游读取数据失败时,需要触发上游的重跑,而在发生严重机器问题时,多个任务的链式重跑,会造成作业的长时间延迟,对于基线作业的及时产出造成严重影响。DAG2.0上实现了一套基于血缘回溯的主动容错策略(如下图),这样的智能血缘回溯,能够避免了层层试探,层层重跑,在集群压力较大时,能够有效的节约运行时间,避免资源浪费。

* **灵活的动态逻辑图执行策略--Conditional join**
分布式SQL中,map join是一个比较常见的优化,其实现原理对小表避免shuffle,而是直接将其全量数据broadcast到每个处理大表的分布式计算节点上,通过在内存中直接建立hash表,完成join操作。map join优化能大量减少额外shuffle和排序开销并避免shuffle过程中可能出现的数据倾斜,提升作业运行性能。但是其局限性也同样显著:如果小表无法fit进单机内存,那么在试图建立内存中的hash表时就会因为OOM而导致整个分布式作业的失败。所以虽然map join在正确使用时,可以带来较大的性能提升,但实际上优化器在产生map join的plan时需要偏保守,导致错失了很多优化机会。而即便是如此,依然没有办法完全避免map join OOM的问题。
基于DAG 2.0的动态逻辑图执行能力,MaxCompute支持了开发的conditional join功能:在对于join使用的算法无法被事先确定时,允许优化器提供一个conditional DAG,这样的DAG同时包括使用两种不同join的方式对应的不同执行计划支路。在实际执行时,AM根据上游产出数据量,动态选择一条支路执行(plan A or plan B)。这样子的动态逻辑图执行流程,能够保证每次作业运行时都能根据实际作业数据特性,选择最优的执行计划,详见下图:

出于对上线节奏把控的考虑,双十一期间conditional join尚未覆盖高优先级作业。双十一期间,我们也看到了重要基线上由于数据膨胀导致Mapjoin hint失效,作业OOM需要临时调参;以及因为Mapjoin未能被正确选中,而导致作业未能选中优化执行计划而延迟完成的情况。在conditional join在重要基线上线后,能够有效的避免这一情况,让基线的产出更加流畅。
**DAG 2.0 双十一线上成果**
双十一作为阿里集团所有技术线的大考,对于DAG2.0这一全新的组件,同样是一个重要的考验,也是DAG2线上升级的一个重要的里程碑:
* 双11当天,DAG2.0覆盖支持线上80%+project。截至目前已完成全面上线,日均支持几百万的离线作业执行。对于signature相同的基线作业,DAG 2.0下instance 运行的overhead开销有1到2倍的降低。
* 双11当天,使用DAG 2.0的高优先级基线在双十一数据洪峰下,没有任何人工干预的前提下,未发生任何作业失败重跑。其中,DAG2.0提供的实时机器管理,backup instance策略等智能容错机制发挥了重要作用。
* 支持开发环境中近百万量级作业,在作业平均规模更大的前提下,双11期间毫秒级(执行时间小于1s的作业)分布作业占比相比1.0提升20%+。新框架上更高效的资源流转率也带来了资源利用率的明显提升:等待在线资源超时而回退的在线作业比例降低了将近50%。
* DAG 2.0还支持了PAI引擎,为双十一期间的搜索、推荐等业务的模型提前训练提供了有力的支持。双十一前PAI平台的所有TensorFlow CPU/GPU作业,就已经全量迁移到DAG 2.0上,其更有效的容错和资源使用的提升,保证了各条业务线上模型的及时产出。
除了基础提升调度能力提升带来的性能红利外,DAG2在动态图亮点功能上也完成了新的突破。包括增强Dynamic Parrellism, LIMIT优化, Conditional Join等动态图功能完成上线或者正在上线推动中。其中Conditional Join一方面保证了优化的执行计划能尽可能的被选用,同时也保证了不会因为错误选择而带来OOM导致作业失败,通过运行时数据统计来动态决定是否使用Mapjoin,保证更加准确决策。双十一前在集团内部做了灰度上线,线上日均生效的conditionl节点**10万+**,其中应用Map join的节点占比超过了**90%**,**0 OOM发生**。推广的过程中我们也收到了各个BU多个用户的真实反馈,使用conditional join后,因为能选择最优的执行计划,多个场景上作业的运行时间,**都从几个小时降低到了30分钟以下**。
**DAG 2.0 展望**
在双十一值班的过程中,我们依然看到了大促场景下因为不同的数据分布特点,数据的倾斜/膨胀对于分布式作业整体的完成时间影响非常大。而这些问题在DAG 2.0完备的动态图调度和运行能力上,都能得到较好的解决,相关功能正在排期上线中。
一个典型的例子是dynamic partition insert的场景,在某个高优先级作业的场景上,一张重要的业务表直接采用动态分区的方式导入数据导致表文件数过多,后续基线频繁访问该表读取数据导致pangu master持续被打爆,集群处于不可用状态。采用DAG2.0的Adaptive Shuffle功能之后,线下验证作业运行时间**由30+小时降低到小于30分钟**,而产生的文件数相比于关闭reshuffle的方式**降低了一个数量级**,在保障业务数据及时产出的前提下,能极大缓解pangu master的压力。动态分区场景在弹内生产和公共云生产都有广阔的应用场景,随着Adaptive Shuffle的上线,dynamic insert将是第一个解决的比较彻底的数据倾斜场景。此外,DAG2.0也持续探索其他数据倾斜(data skew)的处理,例如join skew等,相信随着在2.0上更多优化功能的开发,我们的执行引擎能做到更动态,更智能化,包括数据倾斜问题在内的一众线上痛点问题,将可以得到更好的解决。今天最好的表现,是明天最低的要求。我们相信明年的双十一,在面对更大的数据处理量时,计算平台的双十一保障能够更加的自动化,通过分布式作业运行中的动态化调整,在更少人工干预的前提下完成。
资源调度的交互式抢占
==========
**挑战**
FuxiMaster是fuxi的资源调度器,负责将计算资源分配给不同的计算任务。针对MaxComput超大规模计算场景下,不同应用间多样的资源需求,过去几年资源调度团队对的核心调度逻辑做了极致的性能优化,调度延时控制在了10微秒级别,集群资源的高效流转为MaxComputer历年双十一大促的稳定运行提供了强有力的保障。
而其中高先级基线作业的按时完成是双十一大促成功的重要标志,也是资源保障中的重中之重。除了空闲资源的优先分配,还需要对低优先级作业占用的资源进行腾挪,在不影响集群整体利用率的前提下,快速地将资源分配给高优先级基线作业。
**交互式抢占概述**
在高负载的集群,若高优先级作业无法及时拿到资源,传统的做法是通过抢占,直接杀掉低优先级作业,然后将资源分配给高优先级作业,这种“暴力”抢占有资源快速腾挪的特点,但抢占“杀人”也会导致用户作业中途被杀,计算资源浪费的缺点。交互式抢占是指在明确资源从低优先级流向高优先级的前提下,不立即杀掉低优先级作业,而是通过协议,让低优先级作业尽快在可接受的时间内(目前是90s)快速跑完,既不浪费集群的计算资源,同时也保障了高优先级作业的资源供给。
目前弹内线上针对高优先级SU(schedule unit,是资源管理的基本单位)开启组内交互式抢占,在大多情况下可以保障基线作业的资源供给。然而,目前即使通过交互式抢占也还会存在一些作业无法及时获得资源的情况。例如,高优先级交互式抢占每隔30s的触发处理高优先的SU数量受全局配置约束,而该段时间还存在大量其他早已经提交进来的高优先级SU,会导致该作业的SU被轮空。另外,交互式抢占指令发出后,需要对应instance结束后定向还这份资源,而对应的instance的运行时间都非常长,导致交互式无法及时拿回对应的资源。 基于上述问题,我们进一步优化了交互式抢占策略。
**交互式抢占关键技术**
针对前文提到的几个问题,交互式抢占做了如下优化:
* 通过性能优化,放宽了高优先级每轮处理的SU限制个数
* 交互式抢占超时后强制回收预留的低优先级资源,对于优先启动的、占据大量资源、instance运行时间较长的低优先级作业,需要强制回收资源。
* 采用预留外的资源供给高优先级资源,可以通过预留外的其他资源为交互式抢占的SU继续分配资源,同时抵消对应的交互式抢占部分。
**双十一线上成果**
2019双十一期间,面对远超以往的数据量,所有的高优先级作业顺利按期产出,资源调度方面顺利保障了基线资源供给,其丝般顺滑程度让整个基线保障的过程几乎感受不到资源调度的存在。其中基线作业交互式抢占以及加速功能提供了有效的资源保障能力,及时、有效的抢占到所需资源。下文给出了某个云上集群的资源供给情况。
* **交互式抢占加速为基线作业快速提供可用资源**
从下面几张图中可以看到,在基线时间段(00:00 ~ 09:00), 基线作业超时拿不到资源发起交互式抢占revoke的频率明显高于其他时段, 这意味着通过交互式抢占加速的手段基线作业可以顺利拿到所需资源。双十一期间的线上运行情况,也证明了 在资源压力大的情况下,高优先级基线作业明显通过了交互式抢占revoke获得了资源。

* **基线作业的SU拿资源时间比例分布**
下边为主要几个集群SU拿资源的时间分布 (fuxi基本调度单元), 可以发现这几个集群90%分位拿资源的时间基本都在1分钟左右(**符合线上基线作业等待资源达到90s进行抢占配置预期**)。

[原文链接](https://link.zhihu.com/?target=https%3A//yq.aliyun.com/articles/739645%3Futm_content%3Dg_1000094672)
本文为阿里云内容,未经允许不得转载。