Apache Flume1.8.0用户手册官方文档理解
Flume 1.8.0 User Guide
本博客是对Apache 官网中Flume1.8用户手册的解读,原文点此查看
Introduce
overview
Apache Flume是一种分布式、可靠、可用的系统,它可以从很多不同的源头高效地收集、聚合以及传输大量的日志数据到一个中心数据库。
对Flume的应用其实并不局限于对日志数据的聚合。由于数据源是定制的,因此Flume可以传输大量事件数据,包括但不仅限于网络流量数据、社交媒体生成的数据、邮件消息和其他几乎任何可能产生的数据源。
Apache Flume现在是Apache Software Foundation(Apache软件基金会)的*工程。
System Requirements
1.Java 运行时环境 - Java 1.8 或以上
2.内存 - 为数据源(sources)、通道(channels)或者接收器(sinks)提供足够的内存配置
3.存盘空间 - 为通道(channels)或者接收器(sinks)提供足够的存盘空间配置
4.目录权限- 为代理(agent)提供目录的读/写权限
Architecture
Date flow model
event是Flume传输数据的基本单位,它是指具有一个字节有效负载和一组可选字符串属性的一个单元数据流。
agent是一个(JVM)进程,events可以从它的组件中从外部源流向下一个目的地,其组成见下图:
agent是Flume的核心,在agent中:
source消耗外部源(比如一个web服务器)传送给它的events,外部源以一种被目标Flume source认可的格式发送这些events。比如,一个Arvo Flume source能接受从Avro客户端或者在这个过程中从Arvo sink(接收器)中发送events的其它Flume agent
channel提供一个队列的作用,当source收到event时,它将event存储到一个或多个channel中,channel保存这些event,等待sink来取走。比如file channel,是由本地文件系统支持的
sink将event从channel中取出,将它放入像HDFS这样的外部存储器,或者将它传输给整个过程中的下一个Flume agent的source。
简单地说,source从agent外部接受数据,收集数据,channel存储数据,sink进行相应的数据存储或传输功能。同时,source和sink能异步地向channel中传递或者取走event.
Complex flows
Flume允许用户建立多级工作流,event在到达最终目的地之前可以经过多个agent的处理。它还允许扇入(source可接受多个输入)和扇出(sink可将数据传入多个目的地)流、备份路由(故障转移)用于失败的跳转。
Reliability
在每一个agent中,event是存放在channel中的,只有当event被存放到下一个agent的channel中或者最终的存储库中之后,才能把event从该channel中移除,这保证了Flume的可靠性。
Recoverability
channel要能成功解决event出现错误的问题。Flume提供了一个由本地文件系统支持的持久的文件channel,同时,还提供了一个memory channel能将event简单地存放在一个内存中的队列里,这样比较快,但是当agent消亡之后就不能恢复了。
Setup
Setting up an agent
Flume agent的配置存储在一个遵循java属性文件格式的本地文本文件中的,对一个或多个agent的配置可以在一个配置文件中完成。配置文件中说明了每一个source、channel、sink的属性以及它们在同一个agent中是如何连接在一起处理数据流的。
Configuring individual components
整个处理过程中的每个组件(source、channel、sink)都有名字、类型以及一系列属性来将它们实例化。比如,一个Avro source需要接收数据来源的主机地址(或者IP地址)和端口号;一个memory channel可以有最大队列长度;一个HDFS sink需要知道文件系统的URI,创建文件的路径等。
Wiring the pieces together
通过列出所有source、channel、sink的名字和指定每个sink和sourcede 连接channel,agent就知道该去加载哪些组件以及它们之间的关联。
Starting an agent
agent是由位于bin目录下的一个名为flume-ng的脚本文件来启动的。需要在命令行中配置agent的名字、配置目录和配置文档
本人执行此操作时,出现了一些错误,下面是我的做法:
1、在bin文件夹下新建一个conf文件夹,并将原来conf文件下的flume-conf.properties.template复制到bin下面的conf文件夹中
2.找到conf/flume-env.sh.template 文件中的export JAVA_HOME=xxxxx,将路径改为自己的jdk目录
3.将java.exe复制到bin文件夹中
然后在bin目录下运行命令:flume-ng agent -n $agent_name -c conf -f conf/flume-conf.properties.template
查看bin/log文件,会有所显示
A simple example
如下,我们给出了一个样例配置文件,描述了单点Flume的部署。改配置让用户输入event然后将它们显示到控制台。
将其命名为example.conf并保存到conf目录中
此配置定义了一个名为a1的agent,a1有一个监听来自44444端口的source,一个将event数据缓存到内存的channel和一个将event数据输出到控制台的sink。下面,根据配置文件我们就可以启动一个agent了。
注:由于本人是在winddows上进行配置,官方文档中是在lunix上进行的,所有下面内容和官网不相同。
进入bin目录,打开cmd,输入以下命令:
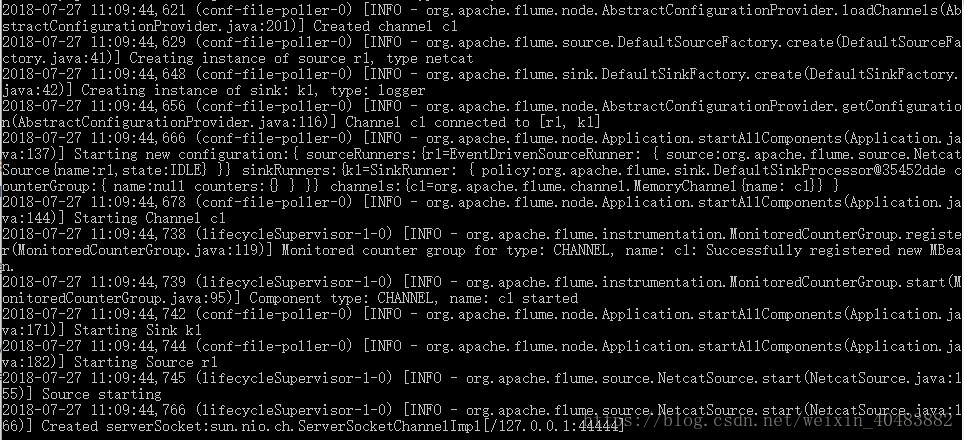
执行效果如下:
从最后一行可以看到,正在监听端口44444
然后,打开一个新的cmd窗口,输入:
telnet localhost 44444
在telnet窗口中输入信息后,可在前面打开的cmd窗口中看到,Flume在控制台上打印出来日志信息。
Using environment variables in configuration files
Flume能在配置中修改环境变量。比如:
注意:它目前只适用于值,不适用于键值对(即只能在“=”右侧)
上述只有一个例子,变量也可以通过其他方式配置,比如在con/flume-env.sh里面设置。
Logging raw data
为了支持event和配置相关的数据记录,除了log4j之外,还需要设置一些Java系统属性。
为了支持配置相关的记录,设置Java系统属性:
-Dorg.apache.flume.log.printconfig=true.这也可以在命令行或者在flume-env.sh文件中的JAVA_OPTS参数中设置
为了支持数据记录,需要将-Dorg.apache.flume.log.rawdata=true按上述方法进行设置。对大多数组件来说,log4j的日志级别必须设为DEBUG或者TRACE才能将具体事件的日志写入Flume日志中。
下面是一个支持配置日志记录及原始数据记录,同时为了控制台输出将log4j的日志级别设为DEBUG的例子:
bin/flume-ng agent --conf conf --conf-file example.conf --name a1 -Dflume.root.logger=DEBUG,console -Dorg.apache.flume.log.printconfig=true -Dorg.apache.flume.log.rawdata=trueZookeeper based Configuration
Flume支持通过ZooKeeper来管理agent配置。但这只是一个实验性的功能。需要将配置文件上传到ZooKeeper,配置文件会存储在ZooKeeper节点数据中。下面是agent a1和a2在ZooKeeper节点树中的结构。
当配置文件上传后,就可使用下面的命令启动agent:
$ bin/flume-ng agent –conf conf -z zkhost:2181,zkhost1:2181 -p /flume –name a1 -Dflume.root.logger=INFO,console| 参数名称 | 默认值 | 描述 |
|---|---|---|
| Z | - | ZooKeeper连接字符串,用逗号连接hostname:port例表P |
| P | /Flume | ZooKeeper中保存配置文件的基本路径 |
Installing third-party plugins
Flume有一个完全基于插件的架构。Flume附带有很多立即可用的source、channel、sink、serializer等,很多实现都是独立于Flume存在的。因为Flume支持通过在flume-evn.sh文件的FLUME_CLASSPATH参数中加入组件的jar引入组件,Flume现在支持一个特殊的称为plugins.d的目录,它可以自动地收集那些打包成特定格式的组件。
The plugins.d directory
plugins.d位于$FLUME_HOME/plugins.d路径,启动时,flume-ng开始脚本会在plugins.d目录下查找符合下面格式的插件并在启动java时将它们引入合适的路径。
Directory layout for plugins
plugins.d文件里的插件最多能有三个子目录:
lib - the plugin’s jar(s)
libext - the plugin’s dependency jar(s)
native - any required native libraries, such as .so files
下面是两个插件的例子:
Data ingestion
Flume支持很多从外部资源获取数据的机制。
RPC
一个包含在Flume发行版本中的Arvo机制可以通过RPC(远程过程调用)机制将给定的文件发送给Flume Arvo source:
$ bin/flume-ng avro-client -H localhost -p 41414 -F /usr/logs/log.10上述命令会将/usr/logs/log.10中的内容发送给正在监听该端口的Flume source
Network streams
Flume supports the following mechanisms to read data from popular log stream types, such as:
Flume支持下列机制来从流行的数据流结构中读取数据,比如:
- Arvo
- Thrift
- Syslog
- Netcat
Setting multi-agent flow
为了能让数据流经多级agents或,上一个agent的sink和当前的source需要时arvo类型,同时sink需要指向source的hostname(或主机地址)和端口号。
Consolidation(聚合)
日志收集中一种很常见的场景是大量的日志生产客户端向少量连接到存储子系统的使用者agents发送数据。比如,从上百个web服务器收集来的日志被发送到12个向HDFS集群写数据的agents.
在Flume中,可以将大量的一级aggents配置为avro sink,全都指向同一个agent的avro source.(也可以使用thrift sources/sinks/clients)第二级agent中的source将所有收到的events聚集到一个channel中,sink再从中取走events并将它们送往最终目的地。
Multiplexing the flow(多路复用流)
Flume支持将event flow传输到一个或多个目的地。这是通过定义流多路复用器实现的,该多路复用器复制或者有选择性地将一个event发送到一个或多个channel中。
上面的例子展示了从名为foo的agent的source扇出的流向3个不同channel的数据流。扇出的数据流可以是复制的,也可以是多路复选的。对于复制流来说每一个event被发送到了这3个channel中的每一个,对于多路复选流来说,当一个event的属性预配置的值相同时,可以被传送到可用channel的子集中。这样的匹配可以设置在agent的配置文件中。
Configuration
正如在前面的部分谈到的那样,Flume agent的配置是像Java属性文件一样有着层次属性设置,是在一个文件中设置的。
Defining the flow
为了定义单个agent中的流,需要将source和sink通过channel连接起来,需要为给定的agent指定sources、channels和sinks,并为source和sink指定channel。一个source可以有多个channel,但一个sink只能有一个channel。格式如下:
比如,当一个名为agent_foo的agent从外部的avro客户端读取数据并将数据通过memory channel发送到HDFS,配置文件(命名为weblog.config)可以这样写:
当一个agent将weblog.config作为它的配置文档时,这个流会被实例化。
Configuring individual components
定义了流之后,需要为每一个 source, sink 和channel设置属性。当设置这些组件的类型和其他属性时,也是按照相同的层次空间命名方式完成的:
为了Flume能理解各组件是什么对象,每一个组件都需要设置“type”属性,每一种source, sink 和 channel类型都有自己的属性列表来完成相应的功能。在前面的例子中,我们定义了一个从avro-AppSrv-source通过名为mem-channel-1的memory channel流向hdfs-Cluster1-sink,下面这个例子展示了每一个组件的属性:
Adding multiple flows in an agent
一个agent可以包含多个source、channel和sink,通过将它们连接起来,可形成多个相互独立的流:
然后,可以将sources和sinks通过它们相应的channel连接起来形成不同的流。比如,需要在一个agent中设置两个流,一个从外部的avro客户端到HDFS,另一个从输出的尾部到avro sink:
Configuring a multi agent flow(配置一个多级agent流)
为了建立多级流,需要将第一跳的avro/thrift sink指向下一跳的avro/thrift source。比如,如果正在使用avro客户端定期向本地Flume代理发送文件(每个event一个文件),那么这个本地agent可以将文件转发给另一个用于存储的agent:
Weblog agent(第一跳) config:
HDFS agent (第二跳)config:
Fan out flow
正如前面所讲,Flume支持扇出 – 从一个source流入多个channel。有两种类型的扇出:复制型和多路复选性。
复制型:每个event流入每个配置了的channel
多路复选型:event流入符合要求的channel子集
通过增加一个channel“选择器”,可以指定source的channel列表和扇出机制。如果需要一个多路复选器则需要进一步明确多路复选规则,不指定的话则默认为是复制器:
多路复选器需要指定从event的属性到channel集合的对应关系。选择器检查每一个event头部中配置的属性,如果符合具体值,则将该event发送到所有匹配上的channel中,如果没有一个匹配的,则送往默认的channel中:
映射允许多个通道有重叠的值。
下面的例子中有一个被多路复选到2条通道中的流。agent_foo中有一个avro source和两个channels分别连接到两个不同的sink:
选择器还支持optional channel,配置方法如下:
选择器首先会尝试向要求的channel中写入,如果其中一个channel失败的话,所有的channel都会重试一次。所有要求的channel都尝试了event之后,选择器会尝试像optional channel中写入,这时发生的错误会被忽略,不会重试。
注意,如果一个头部信息没有和任何有要求的channel匹配的话,那么该event会被写入默认channel,同时会被尝试写入optional channel。如果没有要求的channel,与optional channel匹配仍要写入默认channel。
Flume Sources
Avro Source
监听Arvo端口以及从外部Avro数据流中接受events。粗体为必修的属性:
ipFliterRules示例:
ipFilterRules定义了N个用逗号隔开的网状ipFilter,模式规则如下:
<’allow’ or deny>:<’ip’ or ‘name’ for computer name>: or allow/deny:ip/name:pattern
比如:ipFilterRules=allow:ip:127.,allow:name:localhost,deny:ip:
注意:会应用匹配上的第一个规则,如下所示:
允许来自localhost上的客户端,拒绝其他ip的客户端:allow:name:localhost,deny:ip:
拒绝来自localhost上的客户端,允许其他ip的客户端:deny:name:localhost,allow:ip:
Thrift Source
监听Thrift端口并从外Thrift客户端数据流接收event。Thrift source 通过允许kerberos身份验证配置为安全模式。agent-principal和agent-keytab属性是Thrift source用来进行身份验证的。粗体为必需属性:
Exec Source
Exec source在启动时运行给定的Unix命令,同时期待该进程连续产生标准输出数据(stderr被丢弃,除非logStdErr属性被设置为true)。如果该进程退出,则source也退出,并不再产生数据。粗体为必需属性:
>注意:当使用像Exec source这种单项异步接口时,应用不会保证数据被接受,即完全没有事件交付的保证。为了更强的可靠性保证,可以考虑Spooling Directory Source, Taildir Source或者直接通过SDK与Flume集成。
JMS Source
JMS(Java Message Service)source 能从例如queue或者topic这样的JMS模型中读取消息。任何的JMS供应者都必须接受了ActiveMQ测试才能工作。JMS source提供了可配置的批处理数目、消息选择器、用户名/密码以及从消息到event的转换器。注意JMS jars需要在路径中配置(可通过 plugins.d 目录、命令行或者flume-env.sh文件中的参数配置)。
粗体为必须属性:
Spooling Directory Source
Spooling Directory Source 能监控一个指定的目录,如果出现新的文件时,就会解析文件中的event,当文件被完全写进channel以后,文件会被重命名来表示已经完成(或者被选择性删除)。该source是稳定可靠的。
如果出现下列问题会出错并停止进程:
1、文件在已经被放入spooling文件后被写入
2、文件名被重用
为防止出现以上错误,文件被放入spooling目录时最好加上特定的标记(如时间戳)。
粗体为必须属性:
下面是一个例子:
Taildir Source
注意:这个source只是一个预览版本,在windows不能工作
监控指定文件,当文件被追加新的数据时能几乎实时发现;如果新加数据行正在被写入,source会等待写入完成后再重新尝试读取数据。该source是可靠的。
Taildir Source不会重命名、删除或对被监控文件座任何改变。目前此source不支持监控二进制文件,它是一行一行地读取文本文件。
其属性如下:
下面是一个例子:
Twitter 1% firehose Source (实验性)
警示:这个source是高度实验性的,请谨慎使用
这个实验性的source是通过Streaming API和1%的Twitter样本连接起来,连续地下载Twitter上的消息,将它们转换为Arvo格式,并把这些 Avro events发送到下流的Flume sink。需要用户和访问令牌以及Twitter开发者账号。
Kafka Source
这个source是从Kafka topics中读取消息的消费者。如果有多个Kafka sources,可以将它们配置为同一个消费组,那么每个source会读取topics中的唯一的一组分区。配置如下:
用逗号分隔的topics示例:
用正则表达式匹配的topics示例:
NetCat TCP Source
类似于netcat的source,监听给定的端口号并将每一行文本转换为event,就像nc -k -l [host] [port]一样。换句话说,就是打开特定的端口监听数据。
示例:
NetCat UDP Source
与NetCat TCP Source类似。
示例:
Flume Sinks
HDFS Sink
这个sink将events写入Hadoop分布式文件系统(HDFS),现在支持创建文本和序列文件,并支持这两种文件类型的压缩形式。可以根据运行时间、数据大小或events的数量周期性地滚动文件(关闭当前文件并创建新文件),也可以根据像时间戳、event生成的机器等属性来对数据进行分区。HDFS目录路径可以包含格式化的转义序列,安装了hadoop才能使用这个sink。
下面是支持的转义序列:
正在使用中的文件会在名字末尾添加 ”.tmp”,当文件被关闭之后,后缀会被移除。
粗体为必须属性:
注意:对于所有与时间相关的转义序列,在event的头部中必须存在一个带有“timestamp”(除非hdfs.useLocalTimeStamp设置为true)。自动添加此功能的一种方法是使用TimestampInterceptor。
下面是一个示例:
上面的配置会将时间戳向下取舍为最后的10分钟。比如时间戳为11:54:34 AM, June 12, 2012,那么存储路径为/flume/events/2012-06-12/1150/00.
Hive Sink
这个sink将包含有分割文本或者JSON数据的event直接流到Hive表或者分区,只要数据被提交到了Hive,它们就马上能被Hive查询。flume将要流向的分区可以被提前创建,也可以在缺失的时候创建,来自传入event数据的字段被映射到对应的Hive表的相应列。
Hive表的示例:
一个agent的示例:
Avro Sink
这个sink形成了Flume的分层收集支撑的一半,发送到这个sink的event被转换为Avro events,并被送到配置的主机和端口号
示例如下:
Thrift Sink
发送到这个sink的event被转换为Thrift events,并被送到配置的主机和端口号.通过kerberos验证,能被配置为安全模式
示例如下:
IRC Sink
IRC sink从依附的channel中接收数据,并将数据转接到配置的IRC目的地
示例:
File Roll Sink
将数据保存到本地文件系统
示例:
HBaseSink
将数据写入HBase. Hbase的配置是从第一个 hbase-site.xml中获取的。一个实现了在配置中指定的HbaseEventSerializer的类将events转换到HBase puts或/和增量中,这些puts和增量然后被写入HBase中。
示例:
Kafka Sink
这个sink能将数据发送到Kafka topic
注意:Kafka Sink用FlumeEvent 头部的topic和key属性来将数据发送到 Kafka.如果有topic头部,那么数据会被发送到那个指定的topic,覆盖配置的topic;如果有key头部,会被用来在topic分区之间对数据分区,有相同key的events会被发送到相同的分区,如果没有key头部,那么events会被送到任意分区。
示例:
HTTP Sink
这个sink使用将数据发送到使用HTYP POST命令的远端服务器,event的内容会被当做POST命令的body部分被发送
示例:
Flume Channels
Memory Channel
events被存储在内存的可配置最大大小的队列中。对于需要高吞吐量和可以在agent失误中丢失数据的数据流来说是理想的。
示例:
JDBC Channel
events被储存在由数据库支持的稳定存储中,现在支持嵌入式的Derby,对于需要高可恢复性的数据流来说是很理想的
示例:
Kafka Channel
events被存储在kafka集群中,kafka提供了高度可用性和复制性,万一有一个agent或者一个Kafka broker损坏了,可以立刻从其它sink中得到events
Kafka channel 可以在多种情况下使用:
1、有Flume source 和sink –为event提供了一种可靠且高度可用性的channel
2、有 Flume source和拦截器但是没有sink – 允许将flume events写入Kafka topic,为了其他应用使用
3、有Flume sink,但是没有source – 是一种将events从Kafka发送到像HDFS, HBase等Flume sinks的低延迟、可容错的方法
示例:
File Channel
注意:默认情况下,File Channel使用checkpoint和数据目录的路径,这些路径都位于上面指定的用户主目录中。因此,如果agent中有多个活动的File Channel实例,那么只有一个能够锁定目录并导致另外通道初始化失败。因此,必须为所有配置的通道提供显式路径,最好是在不同的磁盘上。此外,由于文件通道将在每次提交后同步到磁盘,因此可能需要将它与sink/source耦合起来,以便在checkpoint和数据目录无法使用多个磁盘的情况下提供良好的性能。
示例:
Flume Channel Selectors
如果没有定义,则默认为“replicating”
Replicating Channel Selector (default)
粗体为必须属性:
示例:
在上面的例子中,c3是可选的,写入c3失败的话会被直接忽略
Multiplexing (多路)Channel Selector
示例:
Custom Channel Selector
是用户自己对ChannelSelector接口的实现,一个用户通道选择器的类和它的依赖需要被写入agent的类路径,用户选择器通道的类型是它的全类名。
示例:
Flume Sink Processors
sink组允许一个实体中有多个接收器。 接收器处理器可在组内的所有接收器上提供负载平衡功能,或在暂时性故障的情况下实现从一个接收器到另一个接收器的故障转移。
示例:
Default Sink Processor
默认的 sink processor只能接受单一的一个sink,用户可以不为单一的sink创建处理器。
Failover (故障转移)Sink Processor
包含一个sink优先级列表,保证只要有一个可以用,event就能被处理
故障转移机制的工作原理是将失败的event放入一个为它们指定了重试之前的冷却期的池子中,冷却期随着连续的失败而增加
示例:
Load balancing(负载平衡) Sink Processor
负载平衡接收器处理器能在多个sink上负载均衡流,它有一个活动着的接收器以及该接收器的负载的索引列,可以通过轮询方式或者随机选择机制来分发负载,默认为轮询方式。
示例:
Event Serializers
file_roll接收器和hdfs接收器都支持EventSerializer接口。
Body Text Serializer
别名:text
该拦截器将event主体写入输出流,不做任何转换或修改,event 的头部会被忽略
示例:
“Flume Event” Avro Event Serializer
别名:avro_event
该拦截器将Flume events系列化为Avro容器文件,这种模式和在 Avro RPC机制中一样。
示例:
Avro Event Serializer
像“Flume Event” Avro Event Serializer一样将Flume events系列化为Avro容器文件,但是,记录模式是可配置的。记录模式可以指定为Flume配置属性,也可以在事件标头中传递。
示例:
Flume Interceptors
拦截器可以在开发人员定义的标准上修改甚至丢弃events,通过定义拦截器构建类名列表,Flume也支持拦截器链。拦截器是在source的定义中通过空格分隔的列表实现的。
下面是一个创建多个拦截器的例子:
Timestamp Interceptor
该拦截器在event的头部插入处理这个event的以毫秒为单位的时间,
示例:
Host Interceptor
该拦截器插入这个agent运行在的主机的主机名或者主机地址。
示例:
Static Interceptor
该拦截器允许用户在event头部添加一组静态的key和value
目前不支持一次添加多个头部,用户可以自己串接多个static interceptors,每个拦截器定义一个静态的头部
示例:
Remove Header Interceptor
该拦截器可以移除event的一个或多个头部。它可以移除静态定义的头部、满足特定表达式的头部或者列表中的头部。
如果只需要一出一个头部信息,那么通过名自定义比其它两种方法更好。
Flume Properties
Property: flume.called.from.service
flume每30秒定期轮询指定配置文件的更改。如果已有文件第一次被轮询,或者现有文件的修改日期自上次轮询以来发生了更改,那么Flume代理将从配置文件中加载新的配置。重命名或移动文件不会改变其修改时间。当Flume agent轮询一个不存在的文件时,会发生两种情况之一:
1、当agent第一次轮询一个不存在的配置文件时,代理根据flume.call .from.service属性进行操作。如果设置了属性,那么代理将继续轮询(总是在同一时间段——每30秒一次)。如果属性未设置,则代理立即终止。
2、当agent轮询一个不存在的配置文件时,并且这不是第一次轮询文件时,agent不会对这个轮询期间的配置进行更改,agent继续轮询而不是终止。
Log4J Appender
将 Log4j events追加到一个flume agent的avro source,使用这个appender的类路径必须要有flume-ng-sdk(比如, flume-ng-sdk-1.8.0.jar)
简单的log4j.properties 文件:
默认来说,每一个event通过使用toString()放啊或者使用 Log4j layout转换为string,如果这个event是org.apache.avro.generic.GenericRecord, org.apache.avro.specific.SpecificRecord的实例,或者AvroReflectionEnabled属性被设置为true,那么这个event会通过Avro 序列化
使用Avro模式序列化每个event是低效的,因此可以提供一个模式URL,从这个URL模式可以被下游接收器(通常是HDFS接收器)检索到。如果没有指定AvroSchemaUrl,那么模式将作为Flume头部信息。
Sample log4j.properties file configured to use Avro serialization:
使用 Avro 序列化的 log4j.properties文件:
Load Balancing Log4J Appender
将 Log4j events 添加到flume agent的avro source列表中。该appender支持轮询和随机方案来执行负载平衡操作,它还支持一种可配置的回退超时,以便临时从主机集中删除下行agent
示例:
Security
HDFS sink, HBase sink, Thrift source, Thrift sink and Kite Dataset sink都支持Kerberos身份验证。
Tools
File Channel Integrity Tool
验证File channel 中各个event的完整性,并删除损坏的event
启动方式如下:
$bin/flume-ng tool --conf ./conf FCINTEGRITYTOOL -l ./datadirEvent Validator Tool
以特定于应用程序的方式验证File Channel的event,该工具在每个事件上应用用户提供者验证登录,并删除不符合逻辑的事件。
启动方式如下:
$bin/flume-ng tool --conf ./conf FCINTEGRITYTOOL -l ./datadir -e org.apache.flume.MyEventValidator -DmaxSize 2000下面是一个简单的基于大小的事件验证器,它会拒绝大于指定大小的event:
public static class MyEventValidator implements EventValidator {
private int value = 0;
private MyEventValidator(int val) {
value = val;
}
@Override
public boolean validateEvent(Event event) {
return event.getBody() <= value;
}
public static class Builder implements EventValidator.Builder {
private int sizeValidator = 0;
@Override
public EventValidator build() {
return new DummyEventVerifier(sizeValidator);
}
@Override
public void configure(Context context) {
binaryValidator = context.getInteger("maxSize");
}
}
}以上是我对Flume1.8官方文档的解读,如果有不对的地方,欢迎指出。
上一篇: 行为型模式---状态模式
下一篇: 小程序开发之基础内容(icon)