作业2,博客2
程序员文章站
2022-05-15 20:51:33
...
mongodb数据库是一种Nosql(非关系型)数据库,主要用于大量数据的储存,在处理海量数据的时候比mysql更有优势。
要用python去操作mongodb,需在cmd中下载一个驱动程序:pymongo
pip install pymongo
在运行爬虫时,需要提前在cmd中启动mongodb
1.在scrapy的pipelines.py中用代码的方式连接mongodb
import pymongo
# 获取连接mongodb的对象,’127.0.0.1‘为本机地址,'27017'是mongodb启动后默认的端口
client = pymongo.MongoClient('127.0.0.1', port=27017)
# 获取数据库(如果没有douluodalu这个数据库,则创建这个数据库douluodalu)
db = client.douluodalu
# 获取数据库中的集合douluo
collection = db.douluo
2.将爬取的数据item存入mongodb,一定要提前将item转化为字典
class DouluodaluPipeline(object):
def process_item(self, item, spider):
collection.insert(dict(item)) #将item转化为字典
return item
图片示例
3.在settings.py中启用管道DouluodaluPipeline
ITEM_PIPELINES = {
'douluodalu.pipelines.DouluodaluPipeline': 300,
}
图片示例
运行爬虫
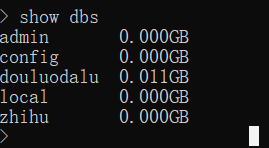
4.在cmd中输入命令show dbs ,可以看到,douluodalu数据库成功建立
5.依次输入一下代码,可以看到douluodalu中存放的爬取的item数据
use douluodalu
db.douluo.find() #douluo为该数据库下的集合名
入库完成
上一篇: 2