5000字总结MySQL单表查询,新手看这一篇足够了!
通过写sql查询,我们可以发现很多简单查询语句主要就是由一些算术操作、字段操作、函数还有各种子句构成的,今天我们从这个角度对mysql单表查询的基础知识进行一个汇总。
-
计算:
- 计算字段
- 算术操作符
- 算术计算
- 字段拼接
- 格式化显示
-
函数:
- 统计函数
- 其他常用函数
-
子句:
- 排序
- 过滤
- 分组
- 分组过滤
- 去重
以这份模拟薪酬统计表为例
字段解读:
id(工号),name(员工姓名),dep(部门),post(职位),years(工作年限),sal(薪酬),bon(奖金)
计算部分
-
1.计算字段说明
很多时候,存在数据库表中的数据不是我们直接需要的,要进行一些计算、清洗或者格式化等操作,所以就有了计算字段的存在,它们不实际存在于数据库表中,是运行时在select语句中创建的。
-
2.算术操作符
算术操作符:+ 加法,- 减法,* 乘法,/(div) 除法,%(mod) 求余
-
3.算术计算
# 统计一下cfo的年薪 select name, sal*12+bon from eg where post = 'cfo';
-
4.字段拼接及列别名
列别名: 别名是一个字段或者值的替换名,可以用关键字as赋予(也可以省略掉as)。
在上面的例子中,如果要对计算后的年薪赋予一个名称,修改第一行代码即可
select name, sal*12+bon as '年薪'
下面我们看下使用concat() 函数来进行字段拼接
# 将员工职位标注在员工名后面
select concat(name, post)
from eg; -
5.格式化显示
上面例子是字段的拼接,但是显然看起来不方便,所以我们进一步看看如何进行格式化显示,假如我们现在需要让每个员工的岗位、年薪显示在一起,构成一个“员工信息”字段
select concat('姓名:', name, '\t', '(', '岗位:', post, '\t', '年薪:', sal*12, ')') as '员工信息'
from eg;
#这里因为有些员工奖金为null,无法有效参与计算,所以年薪的算法一律去掉奖金部分
函数部分
-
1.常用统计函数
count():返回某列的行数
avg():返回某列的平均值
sum():返回某列值的和
max():返回某列最大值
min():返回某列最小值
我们先看下这些函数的简单应用,后面子句中还会提到
select count(id) from eg;
select avg(sal) from eg;
select sum(sal) from eg;
select max(sal) from eg;
select min(sal) from eg;通过上面的统计数据,我们就可以对这个15人团队的整体人力成本有一个大致了解
-
2.文本处理函数
left():返回串左边的字符
length():返回串的长度
locate():找出串的一个子串
lower():将串转换为小写
ltrim():去掉串左边的空格
right():返回串右边的字符
rtrim():去掉串右边的字符
soundex():返回串的soundex值
substring():返回子串的字符
upper():将串转换为大写
-
3.时间日期函数
adddate():增加一个日期(天、周等)
addtime():增加一个时间(时、分等)
curdate():返回当前日期
curtime():返回当前时间
date():返回日期时间的日期部分
datediff():计算两个日期之差
date_add():高度灵活的日期运算函数
date_format():返回一个格式化的日期或时间串
day():返回一个日期的天数部分
dayofweek():对于一个日期,返回对应的星期几
hour():返回一个时间的小时部分
minute():返回一个时间的分钟部分
month():返回一个日期的月份部分
now():返回当前日期和时间
second():返回一个时间的秒部分
time():返回一个日期时间的时间部分
year():返回一个日期的年份部分
-
4.数值处理函数
abs():返回一个数的绝对值
cos():返回一个角度的余弦
exp():返回一个数的指数值
mod():返回除操作的余数
pi():返回圆周率
rand():返回一个随机数
sin():返回一个角度的正弦
sqrt():返回一个数的平方根
tan():返回一个角度的正切
--《mysql必知必会》
上面是从《mysql必知必会》里直接摘录的一些常用函数,我们在这里进行一下汇总,需要的时候可以方便地参考,就不一一举例说明了。
子句部分
-
1.mysql语法顺序
select-->from-->where-->group by-->having-->order by-->limit.
-
2.mysql执行顺序
from --> where --> group by --> having --> select --> distinct --> order by --> limit.
-
3.排序
- 基本排序
查询到的数据一般是以在底层表中出现的顺序显示的,如果我们有排序需求,则不能以此为依赖,而是要严谨地使用order by子句来明确控制。
# 按照员工工龄进行排序
select name, years
from eg
order by years;
- 指定排序方向
上面的操作查询了员工姓名与工龄,并按照工龄进行排序,如果需要让工龄越久的越靠前,我们就可以指定一下排序方向
select name, years
from eg
order by years desc;
# asc(升序)/ desc(降序),默认是升序- 多列排序
下面我们看下如何对多个列进行排序
select name, years, sal, bon from eg order by years asc, sal desc;
这里要注意,多列排序时,当前一列中有相同行时,才对相同行按照下一列的规则继续启动排序。
-
4.过滤
工作用的数据库表中一般包含大量数据,很少会一次全部查询,所以会使用where子句加过滤条件来查询我们需要的数据。
-
认识操作符
- 比较操作符
=(等于),<>、!=(不等于),<(小于),<=(小于等于),>=(大于等于),>(大于),between(在指定两个值之间)
- 逻辑操作符
and(逻辑与),or(逻辑或),in(指定条件范围),not(逻辑非)
- 匹配操作符
like,regexp
-
单条件匹配
select name from eg where years > 3;
select name, years from eg where years != 1; # 不匹配查询
select name from eg where bon is null; # 空值查询 -
多条件匹配
select name, post, sal from eg where post='clerk' and sal>10000;select name, years from eg where sal between 10000 and 20000; # 范围值查询
select name, years from eg where years not in (1, 3, 5); # 指定条件范围,并进行非范围筛选 -
搜索模式
前面提到的匹配方式都是针对已知值,但是实际情况中并不总是这样,有时候我们需要匹配一些字面值,但是我们可能并不清楚她们的全貌,这里就需要用到搜索模式,先认识下简单的通配符:%(任何字符出现任意次数),_(匹配单个字符),这里我们会用到like和regexp两种操作符,一起来看下。
select name from eg where name like 'a%'; # 查询姓名以a开头的员工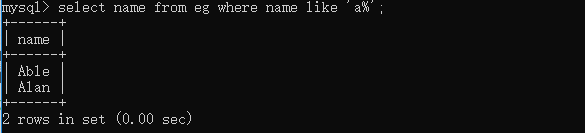 select name from eg where name like '_a%'; # 查询姓名第二个字母为a的员工 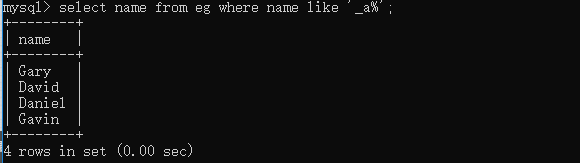 select name from eg where name like 'an'; select name from eg where name regexp 'an'; 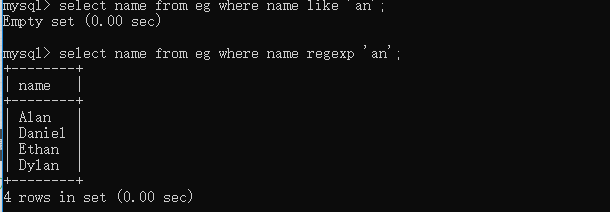 关于regexp的用法这里会涉及到正则表达式,因为正则的内容还比较多,这篇文章里我们只先做一个简单了解,后面会在另一个专题来说明,这里我们注意一下regexp和like的一些使用区别就好,通过上面的例子我们可以看到like匹配的是整个列值,所以当'an'只在列值中出现时,like是不会返回对应值的,而regexp操作时只要被匹配的文本在列值里出现了,那么相应值就会被返回。
-
-
5.分组
通过group by子句可以对数据进行分组,经常会和统计函数一起使用,接下来我们看下它们的具体用法。
-
基本分组
select dep, count(*) as num
from eg
group by dep; # 创建分组并按照部门统计人数 -
分组排序
select years,avg(sal) as avg_sal from eg group by years order by avg_sal desc; # 按工龄分组并分别计算平均薪资
-
多字段分组
select dep, years, avg(sal) as dep_year_avg
from eg
group by dep, years; # 先按照部门,再按照工龄进行分组
-
-
6.分组过滤
如果我们要针对分组进行过滤,按照之前的逻辑就应该在分组后面再加上一个过滤条件,这里需要记住,group by子句后面是不可以再使用where的,这里就引出了having子句,可以用having来筛选成组后的数据。
-
分组过滤
select dep, count(*) as num
from eg
group by dep
having num > 5; # 查询人数大于5的部门 -
where和having的一些使用区别
1.where是在数据分组前进行过滤,having是在数据分组后进行过滤;
2.having可以使用字段别名,where不可以;
3.where是直接从数据表中筛选字段,having是从select查询的字段中再进行筛选,所以having后面跟的字段一定要在前面已经出现过;
4.having可以使用统计函数,where不可以;
5.group by 子句后面只能用having,不能用where;
-
-
7.去重
有时候,我们只想知道想要的数据都有些什么不同类别,而不是全部取出它们,这个时候就需要使用关键字distinct对查询到的数据进行去重处理
select distinct dep from eg; # 查询共有多少部门这里需要注意的是,进行去重操作时,distinct必须在所有字段的最前面,并且它应用于所有字段而不仅是前置它的字段,也就是说如果distinct后面有多个字段,只有它们组合起来的值是相等的才会被去重,看下面例子
select distinct dep, post from eg;不过,当统计函数作为计算字段出现时,distinct可以和统计函数组合使用,就不一定要放在列的最前面了,举个之前练习中遇到的例子,下面语句中distinct的用法也是ok的
select activity_date as day, count(distinct user_id) as active_users
-
8.限制
通过条件查询有时候符合需求的数据记录会太多,这时可以通过limit来限制数量
select name, post
from eg
where post = 'clerk'
limit 3; # 这里指返回不超过3行的数据我们也可以自己定义偏移量,也就是让它从我们想要的行数开始返回
select name, post
from eg
where post = 'clerk'
limit 3, 3;不过这里需要注意,在查询时行数是从0算起的,所以 limit3, 3 指的是从第四行开始返回3行数据,为了更加清晰,mysql5还支持另一种替代语法,如下所示
select name, post
from eg
where post = 'clerk'
limit 3 offset 3;(不过,我个人觉得前面第一种还是挺顺眼的,后面这个反倒看着懵,哈哈哈哈哈~)
如果limit限制的数量大于全部数量的话,也不会报错,会返回全部结果,如下
select name, years
from eg
where years > 5
limit 3;
公众号【dt派】-- 一直在路上,成为更好的人~